Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Managing AWS services and related components
Applications are written involving many AWS Services like S3 for Object Store, RDS for RDBS (SQL), Redis, Kafka, SQS, SNS, Elastic Search, and so on. While each of their configurations needs a few application-centric inputs, there are scores of lower-level nuances around access control, security, and compliance among others.
Using DuploCloud you can pretty much create any service within the Tenant using basic app-centric inputs while the platform will make sure the lower-level nuances are programmed to best practices for security and compliance.
Every service within the Tenant will automatically be reachable to any application running within that tenant. If you need to expose some service from one Tenant to another, see Allow Cross-tenant Access.
DuploCloud adds new AWS services to the platform on almost a weekly basis, if a certain service is not documented here please contact the DuploCloud Team. Even if the feature is currently available, the DuploCloud team will enable the feature in a matter of days.
Supported Services are listed in alphabetical order, following the core services: Containers, Load Balancers, and Storage.
Using containers and DuploCloud Services with AWS EKS and ECS
Containers and Services are critical elements of deploying AWS applications in the DuploCloud platform. Containers refer to Docker containers: lightweight, standalone packages that contain everything needed to run an application including the code, runtime, system tools, libraries, and settings. Services in DuploCloud are microservices defined by a name, Docker image, and a number of replicas. They can be configured with various optional parameters and are mapped to Kubernetes deployment sets or StatefulSets, depending on whether they have stateful volumes.
DuploCloud supports three container orchestration technologies to deploy containerized applications in AWS: Amazon Elastic Container Service (ECS), Amazon Elastic Kubernetes Service (EKS), and Native Docker containers in virtual machines (VMs). Each option provides benefits and challenges depending on your needs and requirements.
Amazon Elastic Container Service (ECS) is a fully managed service that uses its own orchestration engine to manage and deploy Docker containers. It is quite easy to use, integrates well with other AWS services, and is optimized for running containers in the AWS ecosystem. The tradeoff for this simplicity is that ECS is not as flexible or versatile as EKS and is less portable outside the AWS ecosystem.
Amazon Elastic Kubernetes Service (EKS) is a managed service that uses the open-source container orchestration platform Kubernetes. The learning curve is steeper for EKS than ECS, as users must navigate the complexities of Kubernetes. However, EKS users benefit from the excellent flexibility that Kubernetes’ wide range of tools, features, solutions, and portability provides.
Docker is the foundational containerization technology. It is not managed, so the user manually controls the containers and orchestration. Although Docker requires considerably more user input than ECS or EKS, it offers greater control over the VM infrastructure, strong isolation between applications, and supreme portability.
Adding a Service in the DuploCloud Platform is not the same as adding a Kubernetes service. When you deploy DuploCloud Services, the platform implicitly converts your DuploCloud Service into either a deployment set or a StatefulSet. The service is mapped to a deployment set if there are no volume mappings. Otherwise, it is mapped to a StatefulSet, which you can force creation of if needed. Most configuration values are self-explanatory, such as Images, Replicas, and Environmental Variables.
Kubernetes clusters are created during Infrastructure setup using the Administrator -> Infrastructure option in the DuploCloud Portal. The cluster is created in the same Virtual Private Cloud (VPC) as the Infrastructure. Building an Infrastructure with an EKS/ECS cluster may take some time.
Next, you deploy an application within a Tenant in Kubernetes. The application contains a set of VMs, a Deployment set (Pods), and an application load balancer. Pods can be deployed either through the DuploCloud Portal or through kubectl,using HelmCharts.
When you create a service, refer to the registry configuration in Docker -> Services | Kubernetes -> Services | Cloud Services -> ECS -> Services. Select the Service from the NAME column and select the Configuration tab. Note the values in the Environment Variables and Other Docker Config fields.
For example:
{"DOCKER_REGISTRY_CREDENTIALS_NAME":"registry1"}
Configuration and Secret management in AWS
There are many ways to pass configurations to containers at run-time. Although simple to set up, using Environmental Variables can become complex if there are too many configurations, especially files and certificates.
In Kubernetes, you also have the option to populate environment variables from Config Maps or Secrets.
You can use an S3 Bucket to store and pass configuration to the containers:
Create an S3 bucket in the Tenant and add the needed configurations in an S3 Bucket as a file.
Set the S3 Bucket name as an Environmental Variable.
Create a start-up script that defines the entry point of the container to download the file from the S3 bucket into the container, referenced by the Environmental Variable. Do this by:
Similar to using an S3 bucket, you can create values in an SSM parameter store (navigate to Cloud Services -> App Integration, and select the SSM Parameters tab) and set the Name of the parameter in the Environmental Variable. You then use a startup script in the AWS CLI to pull values from SSM and set them for the application in the container, either as an Environmental Variable or as a file.
Use the AWS Secrets Manager to set configs and secrets in Environmental Variables. Use a container startup script in the AWS CLI to copy secrets and set them in the appropriate format in the container.
Use the ECS Task Definition Secrets fields to set the configuration. For example::
Where X_SERVICE_TOKEN is the Secret defined in the JSON and VALUE_FROM is the AWS secret ARN.
See the Kubernetes Configs and Secrets section.
Creating Load Balancers for single and multiple DuploCloud Services
DuploCloud provides the ability to configure Load Balancers with the type of Application Load Balancer, Network Load Balancer, and Classic Load Balancer.
DuploCloud provides the ability to configure Load Balancers with the following types:
Application Load Balancer - An ALB provides outbound connections to cluster nodes inside the EKS virtual network, translating the private IP address to a public IP address as part of its Outbound Pool.
Network Load Balancer - An NLB distributes traffic across several servers by using the TCP/IP networking protocol. By combining two or more computers that are running applications into a single virtual cluster, NLB provides reliability and performance for web servers and other mission-critical servers.
Classic Load Balancer - The legacy AWS Load Balancer (which was retired from AWS support, as of August 2022).
Load Balancers can be configured for Docker Native, EKS-Enabled, and ECS Services from the DuploCloud Portal. Using the Portal, you can configure:
Service Load Balancers - Application Load Balancers specific to one service. (Navigate to Docker -> Services or Kubernetes -> Services, select a Service from the list, and click the Load Balancer tab).
Shared and Global load balancers - Application or Network Load Balancers that can be used as a shared Load Balancer between Services and for Global Server Load Balancing (GSLB). (Navigate to Cloud Services -> Networking and select the Load Balancers tab).
DuploCloud allows one Load Balancer per DuploCloud Service. To share a load balancer between multiple Services, create a Service Load Balancer of type Target Group Only.
See the following pages for specific information on adding Load Balancer Listeners for:
To specify a custom classless inter-domain routing (CIDR) value for an NLB Load Balancer, edit the Load Balancer Listener configuration in the DuploCloud Portal.
Before completing this task, you must add a Load Balancer Listener of Type Network LB.
In the DuploCloud Portal, navigate Docker -> Services or Kubernetes -> Services.
Select the Service name from the NAME column.
Click the Load Balancers tab.
Click Add in the Custom CIDR field of the Edit Load Balancer Listener pane.
Add the Custom CIDR(s) and press ENTER. In the example below 10.180.12.0/22 and 10.180.8.0/22 are added. After the CIDRs are added, you add Security Groups for Custom CIDR(s).
Repeat this procedure for each custom CIDR that you want to add.
Navigate to Administrator -> Infrastructure. The Infrastructure page displays.
From the Name column, select the appropriate Infrastructure.
Click the Security Group Rules tab.
Click Add to add a Security Group. The Add Tenant Security pane displays.
From the Source Type list box, select Ip Address.
From the IP CIDR list box, select Custom. A field labeled CIDR notation of allowed hosts displays.
In the CIDR Notation of allowed hosts field enter a custom CIDR and complete the other required fields.
Click Add to add the Security Group containing the custom CIDR.
Repeat this procedure to add additional CIDRs.
In the DuploCloud Portal, navigate to Cloud Services -> Networking.
Click the Load Balancer tab.
Click Add. The Create a Load Balancer pane displays.
In the Name field, enter a name for the Load Balancer.
From the Type list box, select a Load Balancer type.
From the Visibility list box, select Public or Internal.
Click Create.
Instead of creating a unique Load Balancer for each Service you create, you can share a single Load Balancer between multiple Services. This is helpful when your applications run distributed microservices where the requests use multiple services and route traffic based on application URLs, which you can define with Load Balancer Listener Rules.
To accomplish this, you:
Create a Service Load Balancer with the type Target Group Only. This step creates a Service Load Balancer that includes a Target Group with a pre-defined name.
Create a Shared Load Balancer with the Target Group that was defined.
Create routing rules for the Shared Load Balancer and the Target Group it defines.
In the DuploCloud Portal, navigate Docker -> Services or Kubernetes -> Services.
On the Services page, select the Service name in the Name column.
Click the Load Balancers tab.
If no Load Balancers exist, click the Configure Load Balancer link. If other Load Balancers exist, click Add in the LB listeners card. The Add Load Balancer Listener pane displays.
From the Select Type list box, select Target Group Only.
You can create a Load Balancer Listener with a type of Target Group Only for Docker or EKS and ECS Services based on your application requirement. Complete the other required fields and click Add.
The Target Group Only Service Load Balancer is displayed in the LB Listeners area in the Load Balancers tab on the Services page.
Add a Shared Load Balancer before performing this procedure.
In the Load Balancer tab of the Cloud Services -> Networking page, select the Shared Load Balancer you created. The Load Balancer page with the Listeners tab displays.
In the Listeners tab, click Add. The Load Balancer Listener pane displays.
Complete all fields, specifying the Target Group that was created when you added a Load Balancer with the Type Target Group Only in the previous step.
Click Save. The Shared Load Balancer for the Target Group displays in the Listeners tab.
Create a Shared Load Balancer for the Target Group before performing this procedure.
Rules are not supported for Network Load Balancers (NLBs).
Click Add. The Add LB Listener rule page displays.
Create routing rules for the Target Group by setting appropriate Conditions. Add Routing Rules by specifying Rule Type, Values, and Forward Target Group. Forward Target Group lists all the Target Groups created for Docker Native, K8s, and ECS Services. Specify Priority for multiple rules. Use the X button to delete specific Values.
Click Submit.
View the rules you defined for any Shared Load Balancer.
In the DuploCloud portal, navigate to Cloud Services -> Networking.
Select the Load Balancer tab.
From the Name column, select the Load Balancer whose rules you want to view.
Update attributes for your defined Target Group.
In the DuploCloud portal, navigate to Cloud Services -> Networking.
Select the Load Balancer tab.
From the Name column, select the Load Balancer whose defined Target Group attributes you want to modify.
You can use the Other Settings card in the DuploCloud Portal to set the following features:
WAF Web ACL
Enable HTTP to HTTPS redirects
Enable Access Logging
Set Idle Timeout
Drop invalid headers
In the DuploCloud Portal, navigate to Docker -> Services or Kubernetes -> Service. The Services page displays.
Select the Service to which your Load Balancer is attached from the Name column.
Click the Load Balancers tab.
In the Other Settings card, click Edit. The Other Load Balancer Settings pane displays.
In the Other Load Balancer Settings pane, select any or all options.
Click Save.
Restrict open access to your public Load Balancers by enforcing controlled access policies.
From the DuploCloud Portal, navigate to Administrator -> System Settings.
Select the System Config tab, and click Add. The Add Config pane displays.
From the Config Type list box, select Flags.
From the Key list box, select Deny Open Access To Public LB.
In the Value list box, select True.
Click Submit. Open access to public Load Balancers is restricted.
Set Docker registry credentials
To authenticate with private Docker registries, DuploCloud utilizes Kubernetes secrets of type kubernetes.io/dockerconfigjson. This process involves specifying the registry URL and credentials in a .dockerconfigjson format, which can be done in two ways:
Base64 Encoded Username and Password: Encode the username and password in Base64 and include it in the .dockerconfigjson secret.
Raw Username and Password: Directly use the username and password in the secret without Base64 encoding. This method is supported and simplifies the process by not requiring the auth field to be Base64 encoded.
In the DuploCloud Portal, navigate to Docker -> Services.
From the Docker list box, select Docker Credentials. The Set Docker registry Creds pane displays.
Supply the credentials in the required format and click Submit.
Enable the Docker Shell Service by selecting Enable Docker Shell from the Docker list box.
If you encounter errors such as pull access denied or fail to resolve references due to authorization issues, ensure the secret is correctly configured and referenced in your service configuration. For non-default repositories, explicitly code the imagePullSecrets with the name of the Docker authentication secret to resolve image-pulling issues, as in the example below:
You can pull images from multiple Docker registries by adding multiple Docker Registry Credentials.
In the DuploCloud Portal, click Administrator-> Plan. The Plans page displays.
Select the Plan in the Name column.
Click the Config tab.
Click Add. The Add Config pane displays.
Docker Credentials can be passed using the Environment Variables config field in the Add Service Basic Options page. This method is particularly useful for dynamically supplying credentials without hardcoding them into your service configurations. Refer to the Kubernetes Configs and Secrets section for more details on using environment variables to pass secrets.
Ensure all required secrets, like imagePullSecrets for Docker authentication, are correctly added and referenced in the service configuration to avoid invalid config issues with a service. Reviewing the service configuration for any missing or incorrectly specified parameters is crucial for smooth operation.
Managing Containers and Service with EKS and Native Docker Services
For an end-to-end example of creating an EKS Service, see this tutorial.
For a Native Docker Services example, see this tutorial.
In the DuploCloud Portal, navigate to Kubernetes -> Services.
Click Add. The Basic Options section of the Add Service page displays.
In the Service Name field, give the Service a name (without spaces).
From the Cloud list box, select AWS.
From the Platform list box, select EKS Linux.
In the Docker Image field, enter the Docker image.
Optionally, enter any allocation tags in the Allocation Tag field.
From the Replica Strategy list box, select a replication strategy. Refer to the informational ToolTip ( ) for more information.
Specify the number of replicas in the Replicas field (for Static replica strategy). The number of replicas you define must be less than or equal to the number of Hosts in the fleet.
In the Replica Placement list box (for Static or Horizontal Pod Autoscaler replication strategies) select First Available, Place on Different Hosts, Spread Across Zones, or Different Hosts and Spread Across Zones. Refer to the informational ToolTip ( ) for more information.
Optionally, enter variables in the Environmental Variables field.
In the Force StatefulSets list box, select Yes or No (for Static or Horizontal Pod Autoscaler replication strategies).
Optionally, select Tolerate spot instances (for Static or Horizontal Pod Autoscaler replication strategies)
Click Next. The Add Service, Advanced Options page displays.
Configure advanced options as needed. For example, you can implement Kubernetes Lifecycle Hooks in the Other Container Config field (optional).
Click Create. The Service is created.
From the DuploCloud Portal, navigate to Kubernetes -> Services. Select the Service from the NAME column. The Service details page displays.
Using the Services page, you can start, stop, and restart multiple services simultaneously.
In the DuploCloud Portal, navigate to Kubernetes -> Services.
Use the checkbox column to select multiple services you want to start or stop at once.
From the Service Actions menu, select Start Service, Stop Service, or Restart Service.
Your selected services are started, stopped, or restarted as you specified.
Using the Import Kubernetes Deployment pane, you can add a Service to an existing Kubernetes namespace using Kubernetes YAML.
In the DuploCloud Portal, select Kubernetes -> Services from the navigation pane.
Click Add. The Add Service page displays.
Click the Import Kubernetes Deployment button in the upper right. The Import Kubernetes Deployment pane displays.
Paste the deployment YAML code, as in the example below, into the Import Kubernetes Deployment pane.
Click Import.
In the Add Service page, click Next.
Click Create. Your Native Kubernetes Service is created.
You can supply advanced configuration options with EKS in the DuploCloud Portal in several ways, including the advanced use cases in this section.
In the DuploCloud Portal, navigate to Administrator -> System Settings.
Click the System Config tab.
Click Add. The Add Config pane displays.
From the Config Type list box, select, Flags.
From the Key list box, select Block Master VPC CIDR Allow in EKS SG.
From the Value list box, select True.
Click Submit. The setting is displayed as BlockMasterVpcCidrAllowInEksSg in the System Config tab.
You can display and manage the Containers you have defined in the DuploCloud portal. Navigate to Kubernetes -> Containers.
Logs
Displays container logs. When you select this option, the Container Logs window displays. Use the Follow Logs option (enabled by default) to monitor logging in real-time for a running container. See the graphic below for an example of the Container Logs window.
State
Displays container state configuration, in YAML code, in a separate window.
Container Shell
Host Shell
Accesses the Host Shell.
Delete
Deletes the container.
DuploCloud provides you with a Just-In-Time (JIT) security token, for fifteen minutes, to access the kubectl cluster.
In the DuploCloud Portal, select Administrator -> Infrastructure from the navigation pane.
Select the Infrastructure in the Name column.
Click the EKS tab.
Copy the temporary Token and the Server Endpoint (Kubernetes URL) Values from the Infrastructure that you created. You can also download the complete configuration by clicking the Download Kube Config button.
Run the following commands, in a local Bash shell instance:
You have now configured kubectl to point and access the Kubernetes cluster. You can apply deployment templates by running the following command:
If you need security tokens of a longer duration, create them on your own. Secure them outside of the DuploCloud environment.
See this section in the Duplocloud Kubernetes documentation.
See this section in the DuploCloud Kubernetes documentation.
See this section in the DuploCloud documentation.
See Kubernetes Pod Toleration for examples of specifying K8s YAML for Pod Toleration.
Working with Load Balancers using AWS EKS
If you need to create an Ingress Load Balancer, refer to the EKS Ingress page in the DuploCloud Kubernetes User Guide.
For an end-to-end example of deploying an application using an EKS Service, see the AWS Quick Start Tutorial and choose the Creating an EKS Service option.
In the DuploCloud Portal, navigate Kubernetes -> Services.
On the Services page, select the Service name in the Name column.
Click the Load Balancers tab.
If no Load Balancers exist, click the Configure Load Balancer link. If other Load Balancers exist, click Add in the LB listeners card. The Add Load Balancer Listener pane displays.
From the Select Type list box, select a Load Balancer Listener type based on your Load Balancer.
Complete other fields as required and click Add to add the Load Balancer Listener.
To specify a custom classless inter-domain routing (CIDR) value for an NLB Load Balancer, edit the Load Balancer Listener configuration in the DuploCloud Portal.
Before completing this task, you must add a Load Balancer Listener of Type Network LB.
In the DuploCloud Portal, navigate to Kubernetes -> Services.
On the Services page, select the Service name in the Name column.
Click the Load Balancers tab.
Click Add in the Custom CIDR field of the Edit Load Balancer Listener pane.
Add the Custom CIDR(s) and press ENTER. In the example below 10.180.12.0/22 and 10.180.8.0/22 are added. After the CIDRs are added, you add Security Groups for Custom CIDR(s).
Repeat this procedure for each custom CIDR that you want to add.
Navigate to Administrator -> Infrastructure. The Infrastructure page displays.
From the Name column, select the appropriate Infrastructure.
Click the Security Group Rules tab.
Click Add to add a Security Group. The Add Tenant Security pane displays.
From the Source Type list box, select Ip Address.
From the IP CIDR list box, select Custom. A field labeled CIDR notation of allowed hosts displays.
In the CIDR Notation of allowed hosts field enter a custom CIDR and complete the other required fields.
Click Add to add the Security Group containing the custom CIDR.
Repeat this procedure to add additional CIDRs.
In the DuploCloud Portal, navigate to Cloud Services -> Networking.
Click the Load Balancer tab.
Click Add. The Create a Load Balancer pane displays.
In the Name field, enter a name for the Load Balancer.
From the Type list box, select a Load Balancer type.
From the Visibility list box, select Public or Internal.
Click Create.
Instead of creating a unique Load Balancer for each Service you create, you can share a single Load Balancer between multiple Services. This is helpful when your applications run distributed microservices where the requests use multiple services and route traffic based on application URLs, which you can define with Load Balancer Listener Rules.
To accomplish this, you:
Create a Service Load Balancer with the type Target Group Only. This step creates a Service Load Balancer that includes a Target Group with a pre-defined name.
Create a Shared Load Balancer with the Target Group that was defined.
Create routing rules for the Shared Load Balancer and the Target Group it defines.
In the DuploCloud Portal, navigate Kubernetes -> Services.
On the Services page, select the Service name in the Name column.
Click the Load Balancers tab.
If no Load Balancers exist, click the Configure Load Balancer link. If other Load Balancers exist, click Add in the LB listeners card. The Add Load Balancer Listener pane displays.
From the Select Type list box, select Target Group Only.
You can create a Load Balancer Listener with a type of Target Group Only for Docker Mode or Native EKS and ECS Services based on your application requirement. Complete the other required fields and click Add.
The Target Group Only Service Load Balancer is displayed in the LB Listeners area in the Load Balancers tab on the Services page.
Add a Shared Load Balancer before performing this procedure.
In the Load Balancer tab of the Cloud Services -> Networking page, select the Shared Load Balancer you created. The Load Balancer page with the Listeners tab displays.
In the Listeners tab, click Add. The Load Balancer Listener pane displays.
Complete all fields, specifying the Target Group that was created when you added a Load Balancer with the Type Target Group Only in the previous step.
Click Save. The Shared Load Balancer for the Target Group displays in the Listeners tab.
Create a Shared Load Balancer for the Target Group before performing this procedure.
Rules are not supported for Network Load Balancers (NLBs).
Click Add. The Add LB Listener rule page displays.
Create routing rules for the Target Group by setting appropriate Conditions. Add Routing Rules by specifying Rule Type, Values, and Forward Target Group. Forward Target Group lists all the Target Groups created for Docker Native, K8s, and ECS Services. Specify Priority for multiple rules. Use the X button to delete specific Values.
Click Submit.
View the rules you defined for any Shared Load Balancer.
In the DuploCloud portal, navigate to Cloud Services -> Networking.
Select the Load Balancer tab.
From the Name column, select the Load Balancer whose rules you want to view.
Update attributes for your defined Target Group.
In the DuploCloud portal, navigate to Cloud Services -> Networking.
Select the Load Balancer tab.
From the Name column, select the Load Balancer whose defined Target Group attributes you want to modify.
The Update Target Group Attributes pane displays.
Find the attribute you want to update in the Attribute column and update the associated value in the Value column.
Click Update to save the changes.
To enable stickiness, complete steps 1-5 for Updating Target Group Attributes above. On the Update Target Group Attributes pane, in the Value field for stickiness.enabled, enter true. Update additional stickiness attributes, if needed. Click Update to save the changes.
You can use the Other Settings card in the DuploCloud Portal to set the following features:
WAF Web ACL
Enable HTTP to HTTPS redirects
Enable Access Logging
Set Idle Timeout
Drop invalid headers
In the DuploCloud Portal, navigate to Kubernetes -> Services. The Services page displays.
Select the Service to which your Load Balancer is attached from the Name column.
Click the Load Balancers tab.
In the Other Settings card, click Edit. The Other Load Balancer Settings pane displays.
In the Other Load Balancer Settings pane, select any or all options.
Click Save.
Managing Containers and Service with ECS
For an end-to-end example of creating an ECS Task Definition, Service, and Load Balancer, see this tutorial.
Using the Services tab in the DuploCloud Portal (navigate to Cloud Services -> ECS and select the Services tab), you can display and manage the Services you have defined.
For ECS Services, select the Service Name and click the Actions menu to Edit or Delete Services, in addition to performing other actions, as shown below.
You can display and manage the Containers you have defined in the DuploCloud portal. Navigate to Kubernetes -> Containers.
Logs
Displays container logs.
State
Displays container state configuration, in YAML code, in a separate window.
Container Shell
Host Shell
Accesses the Host Shell.
Delete
Deletes the container.
You can create up to five (5) containers for ECS services by defining a Task Definition.
To designate a container as Essential, see Defining an Essential Container.
In the DuploCloud Portal, navigate to Cloud Services -> ECS.
In the Task Definitions tab, click Add. The Add Task Definition page displays.
Specify a unique Name for the Task Definition.
From the vCPUs list box, select the number of CPUs to be consumed by the task and change other defaults, if needed.
In the Container - 1 area, specify the Container Name of the first container you want to create.
In the Image field, specify the container Image name, as in the example above.
Specify Port Mappings, and Add New mappings or Delete them, if needed.
Click Submit. Your Task Definition for multiple ECS Service containers is created.
To edit the created Task Definition in order to add or delete multiple containers, select the Task Definition in the Task Definitions tab, and from the Actions menu, select Edit Task Definition.
In AWS ECS, an essential container is a key component of a task definition. An essential container is one that must successfully complete for the task to be considered healthy. If an essential container fails or stops for any reason, the entire task is marked as failed. Essential containers are commonly used to run the main application or service within the task.
By designating containers as essential or non-essential, you define the dependencies and relationships between the containers in your task definition. This allows ECS to properly manage and monitor the overall health and lifecycle of the task, ensuring that the essential containers are always running and healthy.
To designate a container as Essential, follow the Creating multiple containers for ECS Services using a Task Definition procedure to create your containers, but before creating the container you want to designate as Essential, in the Container definition, select the Essential Container option, as in the example below.
Fargate is a technology that you can use with ECS to run containers without having to manage servers or clusters of EC2 instances.
For information about Fargate, contact the DuploCloud support team.
Follow this procedure to create the ECS Service from your Task Definition and define an associated Load Balancer to expose your application on the network.
Create an AWS API Gateway using a REST API from the DuploCloud Portal
To create an AWS API Gateway using a REST API from the DuploCloud Portal, navigate to Cloud Services -> Networking, and click Add on the Api Gateway tab. The REST API generates security policies that make the API Gateway accessible to other resources (like Lambda functions) within the Tenant. After the REST API has been created in the DuploCloud Portal, all other configurations (e.g., defining methods and resources or pointing to lambda functions) should be done in the AWS Console. The console can be reached from the DuploCloud Portal by navigating to Cloud Services -> Networking, selecting the Api Gateway tab, and clicking the Console button under the Actions menu.
Make private AWS API Gateway instances (associated with VPC endpoints) accessible from your machines by constructing a URL, as shown below. Replace REST_API_ID with your API Gateway instance's unique identifier (API ID), VPCE_ID with your VPC Endpoint ID (VPCE ID), REGION with the specified AWS region, and STAGE with the development stage (e.g., prod, dev, test).
https://{REST_API_ID}-{VPCE_ID}.execute-api.{REGION}.amazonaws.com/{STAGE}
The resulting URL will point to the specific API Gateway instance associated with the API ID and VPC Endpoint ID in the specified AWS region and stage. With this URL, you can make requests over the default open VPN to the private API Gateway.
Run AWS batch jobs without installing software or servers
You can perform AWS batch job processing directly in the DuploCloud Portal without the additional overhead of installed software, allowing you to focus on analyzing results and diagnosing problems.
Create scheduling policies to define when your batch job runs.
From the DuploCloud Portal, navigate to Cloud Services -> Batch page, and click the Scheduling Policies tab.
Click Add. The Create Batch Scheduling Policy page displays.
Create batch job scheduling policies using the AWS documentation. The fields in the AWS documentation map to the fields on the DuploCloud Create Batch Scheduling Policy page.
Click Create.
AWS compute environments (Elastic Compute Cloud [EC2] instances) map to DuploCloud Infrastructures. The settings and constraints in the computing environment define how to configure and automatically launch the instance.
In the DuploCloud Portal, navigate to Cloud Services -> Batch.
Click the Compute Environments tab.
Click Add. The Add Batch Environment page displays.
In the Compute Environment Name field, enter a unique name for your environment.
From the Type list box, select the environment type (On-Demand, Spot, Fargate, etc.).
Modify additional defaults on the page or add configuration parameters in the Other Configurations field, as needed.
Click Create. The compute environment is created.
After you define job definitions, create queues for your batch jobs to run in. For more information, see the AWS instructions for creating a job queue.
From the DuploCloud Portal, navigate to Cloud Services -> Batch page, and click the Queues tab.
Click Add. The Create Batch Queue page displays.
Create batch job queues using the AWS documentation. The fields in the AWS documentation map to the fields on the DuploCloud Create Batch Queue page.
Click Create. The batch queue is created.
In the Priority field, enter a whole number. Job queues with a higher priority number are run before those with a lower priority number in the same compute environment.
Before you can run AWS batch jobs, you need to create job definitions specifying how batch jobs are run.
From the DuploCloud Portal, navigate to Cloud Services -> Batch, and click the Job Definitions tab.
Click Add. The Create Batch Job Definition page displays.
Define your batch jobs using the AWS documentation. The fields in the AWS documentation map to the fields on the DuploCloud Create Batch Job Definition page.
Click Create. The batch job definition is created.
Add a job for AWS batch processing. See the AWS documentation for more information about batch jobs.
After you configure your compute environment, navigate to Cloud Services -> Batch and click the Jobs tab.
Click Add. The Add Batch Job page displays.
On the Add Batch Job page, fill the Job Name, Job Definition, Job Queue, and Job Properties fields.
Optionally, if you created a scheduling policy to apply to this job, paste the YAML code below into the Other Properties field.
Click Create. The batch job is created.
As you create a batch job, paste the following YAML code into the Other Properties field on the Add Batch Job page. Replace the scheduling priority override value ("1" in this example) with an integer representing the job's scheduling priority, and replace SHARE_IDENTIFIER with the job's share identifier. For more information, see the AWS documentation.
Navigate from the DuploCloud Portal to Cloud Services -> Batch, and click the Jobs tab. The jobs list displays.
Click the name of the job to view job details such as job status, ID, queue, and definition.
Use the AWS Best Practices Guide for information about running your AWS batch jobs.
Create ElastiCache for Redis database and Memcache memory caching
Amazon ElastiCache is a serverless, Redis- and Memcached-compatible caching service delivering real-time, cost-optimized performance for modern applications.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
Select the ElastiCache tab, and click Add. The Create a ElastiCache page displays.
Provide the database Name.
Select the number of replicas in the Replicas field.
In the Type list box, select Memcached.
Select the Memcache Version.
Select the node size in the Size list box.
Click Create. The Memcached ElastiCache instance is created.
Pass the cache endpoint to your application through the Environment Variables via the AWS Service.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
Select the ElastiCache tab, and click Add. The Create an ElastiCache page displays.
Provide the database Name.
Select the number of Replicas.
Optionally, if you selected more than 2 replicas, enable Automatic Failover. When automatic failover is enabled and the primary Redis node in the cluster fails, one of the read replicas is automatically promoted to become the new primary node.
Optionally, enable Cluster Mode.
In the Type field, select Redis.
In the Size list box, select the node size.
Optionally, complete the Redis Version, Parameter Group Name, KMS (Optional), and Encryption At Transit fields.
Optionally, complete the snapshot settings to configure backup:
Snapshot Name: A label you give to the snapshot for easy identification.
Snapshot ARNs: The link to a specific backup file stored in Amazon S3 that you want to reference or use.
Snapshot Retention Limit: The maximum number of snapshots you want to keep; older ones will be automatically deleted when this limit is reached.
Snapshot Window Start Time: The time when your automated snapshot process will begin.
Snapshot Window Duration in hours: The length of time allowed for taking the snapshots automatically.
Optionally, click the CloudWatch link above the Log Delivery Configuration field to configure the Redis instance to deliver its engine logs to Amazon CloudWatch Logs. The Add CloudWatch Logs: Log Delivery Configuration pane displays. Complete the Log Format, Log Type, and Log Group fields. Click Add Config. The configuration is added to the Log Delivery Configuration field.
Click Create. The Redis database instance is created
When a Redis instance in an AWS environment is experiencing connection issues, ensure the Security Group (SG) configuration allows VPN traffic to port 6379. Then, using the nc command, verify the Redis instance's accessibility.
If you encounter local DNS resolution problems, consider changing your DNS provider or connecting directly using the Redis instance's IP address, which can be obtained via the dig command.
For persistent DNS issues, resetting your router or using external DNS query tools may help. If other troubleshooting steps fail, exploring AWS network interfaces can offer additional insights.
Working with Load Balancers in a Native Docker Service
For an end-to-end example of deploying an application using a Native Docker Service, see the AWS Quick Start Tutorial and choose the Creating a Native Docker Service option.
In the DuploCloud Portal, navigate to Docker -> Services.
Select the Service that you created.
Click the Load Balancers tab.
Click the Configure Load Balancer link. The Add Load Balancer Listener pane displays.
From the Select Type list box, select your Load Balancer type.
Complete other fields as required and click Add to add the Load Balancer Listener.
When the LB Status card displays Ready, your Load Balancer is running and ready for use.
In the LB Listeners area, select the Edit Icon () for the NLB Load Balancer you want to edit. The Edit Load Balancer Listener pane displays.
Note the name of the created Target Group by clicking the Info Icon ( ) for the Load Balancer in the LB Listener card and searching for the string TgName. You will select the Target Group when you create a Shared Load Balancer for the Target Group.
In the Listeners tab, in the Target Group row, click the Actions menu ( ) and select Manage Rules. You can also select Update attributes from the Actions menu, as well, to dynamically update Target Group attributes. The Listener Rules page displays.
In the Listeners tab, in the appropriate Target Group row, click the Actions menu ( ) and select Manage Rules.
In the Listeners tab, in the appropriate Target Group row, click the Actions menu ( ) and select Update attributes.
Use the Options Menu ( ) in each Container row to display Logs, State, Container Shell, Host Shell, and Delete options.
Accesses the Container Shell. To access the Container Shell option, you must first set up .
In the LB Listeners area, select the Edit Icon () for the NLB Load Balancer you want to edit. The Edit Load Balancer Listener pane displays.
Note the name of the created Target Group by clicking the Info Icon ( ) for the Load Balancer in the LB Listener card and searching for the string TgName. You will select the Target Group when you create a Shared Load Balancer for the Target Group.
In the Listeners tab, in the Target Group row, click the Actions menu ( ) and select Manage Rules. You can also select Update attributes from the Actions menu, as well, to dynamically update Target Group attributes. The Listener Rules page displays.
In the Listeners tab, in the appropriate Target Group row, click the Actions menu ( ) and select Manage Rules.
In the Listeners tab, in the appropriate Target Group row, click the Actions menu ( ) and select Update Target Group attributes.
Use the Options Menu ( ) in each Container row to display Logs, State, Container Shell, Host Shell, and Delete options.
Accesses the Container Shell. To access the Container Shell option, you must first set up .
Click the Plus Icon ( ) to the left of the Primary label, which designates that the first container you are defining is the primary container. The Container - 2 area displays.
Use the and icons to collapse and expand the Container areas as needed. Specify Container Name and Image name for each container that you add. Add more containers by clicking the Add Icon ( ) to create up to five (5) containers, in each container area. Delete containers by clicking the Delete ( X ) Icon in each container area.
Databases supported by DuploCloud AWS
DuploCloud supports the following databases for AWS. Use the procedures in this section to set them up.
RDS (MariaDB, MySQL, PostgreSQL, SQL-Express, SQL-Web, SQL-Standard, Aurora MySQL, Aurora MySQL Serverless, Aurora PostgreSQL, Aurora PostgreSQL Serverless)
ElastiCache (Redis, Memcached)
When using DynamoDB in DuploCloud AWS, the required permissions to access the DynamoDB from a virtual machine (VM), Lambda functions, and containers are provisioned automatically using Instance profiles. Therefore, no Access Key is required in the Application code.
When you write application code for DynamoDB in DuploCloud AWS, use the IAM role/Instance profile to connect to these services. If possible, use the AWS SDK constructor, which uses the region.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
Select the DynamoDB tab.
Click Add. The Create a DynamoDB Table pane displays.
Specify the DynamoDB name in the Table Name field, and complete the other required fields (Primary Key, Key Type, and Attribute Type).
Click Create.
For detailed guidance about configuring the duplocloud_aws_dynamodb_table, refer to the Terraform documentation. This resource allows for creating and managing AWS DynamoDB tables within DuploCloud.
Perform additional configuration, as needed, in the AWS Console by clicking the >_ Console icon. In the AWS console, you can configure the application-specific details of DynamoDB database tables. However, no access or security-level permissions are provided.
After creating a DynamoDB table, you can retrieve the final name of the table using the .fullname attribute, which is available in the read-only section of the documentation. This feature is handy for applications that dynamically access table names post-creation. If you encounter any issues or need further assistance, please refer to the documentation or contact support.
Working with Load Balancers using AWS ECS
Before you create an ECS Service and Load Balancer, you must create a Task Definition to run the Service. You can define multiple containers in your Task Definition.
For an end-to-end example of deploying an application using an ECS Service, see the AWS Quick Start Tutorial and choose the Creating an ECS Service option.
Tasks run until an error occurs or a user terminates the Task in the ECS Cluster.
Navigate to Cloud Services -> ECS.
In the Task Definitions tab, select the Task Definition Family Name. This is the Task Definition Name that you created prepended by a unique DuploCloud identifier.
In the Service Details tab, click the Configure ECS Service link. The Add ECS Service page displays.
In the Name field, enter the Service name.
In the LB Listeners area, click Add. The Add Load Balancer Listener pane displays.
From the Select Type list box, select Application LB.
In the Container Port field, enter a container port number.
In the External Port field, enter an external port number.
From the Visibility list box, select an option.
In the Heath Check field, enter a path (such as /) to specify the location of Kubernetes Health Check logs.
From the Backend Protocol list box, select HTTP.
From the Protocol Policy list box, select HTTP1.
Select other options as needed and click Add.
On the Add ECS Service page, click Submit.
In the Service Details tab, information about the Service and Load Balancer you created is displayed.
Verify that the Service and Load Balancer configuration details in the Service Details tab are correct.
Enhance performance and cut costs by using the AWS GP3 Storage Class
GP3, the new storage class from AWS, offers significant performance benefits as well as cost savings when you set it as your default storage class. By using GP3 storage classes instead of GP2 storage classes, you get a baseline of 3000 IOPS, without any additional fees. You can also configure workloads that used a gp2 volume of up to 1000 GiB in capacity with a gp3 volume.
If the volume size is greater than 1000 GiB, check the actual IOPS driven by the workload and choose a corresponding value.
For information about migrating your type GP2 Storage Classes to GP3, see this AWS blog.
To set GP3 as your default Storage Class for future allocations, you must add a custom setting in your Infrastructure.
In the DuploCloud Portal, navigate to Administrator -> Infrastructure. The Infrastructure page displays.
From the Name column, select the Infrastructure to which you want to add a custom setting (for the default G3 storage class).
Click the Settings tab.
Click Add. The Infra - Set Custom Data pane displays.
In the Setting Name field, select Other from the list box.
In the Custom Setting field, select DefaultK8sStorageClass from the list box.
in the Setting Value field, enter gp3.
Click Set.
Configuring a CloudFront distribution in DuploCloud
CloudFront is an AWS content delivery network (CDN) service. It accelerates the delivery of your websites, APIs, video content, and other web assets to users by caching content at edge locations closer to the user.
Before creating a CloudFront distribution:
Upload your static assets to the S3 bucket.
From the DuploCloud Portal, navigate to Cloud Services -> Networking.
Select the CloudFront tab, and click Add. The Add Distribution page displays.
In the Name field, enter a name for the distribution.
In the Root Object field, specify the root object that will be returned when accessing the domain's root (in this example, "index.html"). The root object should not start with "/."
From the Certificate list box, select the ACM certificate for distribution. Only certificates in US-East-1 can be used. If a certificate is not already present, request one in AWS and add it to the DuploCloud Plan.
In the Certificate Protocol Version item list, select the correct certificate protocol.
Optionally, enter any alternate domain name(s) you want to connect to your CloudFront distribution in the Aliases section. For aliases managed by DuploCloud, CNAME mapping is done automatically. For other aliases, manually set up CNAME in your DNS management console.
In the Origins area, enter the location(s) where the content is stored (e.g., an S3 bucket or HTTP server endpoint).
In the Domain Name field, select the correct S3 bucket, or select Other and enter a custom endpoint.
A unique ID will be pre-populated from the domain name. If needed, the ID can be changed.
Optionally, enter a Path (a path will be suffixed to the origin's domain name [URL] while fetching content). Enter static if the content is in an S3 bucket under the prefix static. For a custom URL where all APIs have a prefix like v1, enter v1.
In the Default Cache Behaviors area, select the Cache Policy ID and Target Origin to fetch the content.
In the Custom Cache Behaviors area, enter additional policies and path patterns if needed.
Cache Policy ID - Select one of the AWS-defined cache policies, or choose Other and enter a custom cache policy.
Path Pattern - For requests matching the pattern, enter the specific origin and cache policy to be used. For example, if api/* is entered, all requests that start with the prefix API will be routed to this origin.
Target Origin - Choose the origin that should be used for your custom path.
Note: If the S3 bucket and CloudFront distribution are in the same Tenant, DuploCloud creates an Origin Access Identity and updates the bucket policy to allow GetObject for Cloudfront Origin Access Identity. You do not need to configure any additional S3 bucket permissions.
When creating an AWS CloudFront distribution for a load balancer using Terraform in DuploCloud, ensure to include the comment field in your Terraform configuration as it acts as a required field for the resource name, despite being listed as optional in the documentation. This adjustment is crucial for successful deployment.
Select the Tenant from the Tenant list box.
Navigate to Cloud Services -> Serverless, select the Lambda tab, and click Add.
Select the Edge lambda checkbox. This will create a lambda function in us-east-1 along with the necessary permissions.
Complete the necessary fields and click Submit.
Select the Tenant from the Tenant list box.
Navigate to Cloud Services -> Networking, select the CloudFront tab, and click Add.
Complete the necessary fields. Make sure to select the lambda function created above in Function Associations.
Click Submit.
Note: DuploCloud displays all versions of the lambda function, so the same function will appear multiple times with V1, V2, and so forth.
Once the deployment status becomes Deployed, visit the domain name to see the lambda function invocation.
Create a maintenance page to inform users that your website or application is temporarily unavailable. By clearly communicating the service's status, you can help manage user expectations and provide a better user experience.
The default origin should point to your app URL ui.mysite.com.
Create a new S3 bucket to store your maintenance pages. In the S3 bucket, create a prefix/folder called maintpage.
Upload your maintenance page assets (.html, .css, .js, etc.) into an S3 bucket inside the maintpage folder.
Add a new S3 Origin pointing to the S3 bucket that contains the maintenance static assets.
Add new Custom Cache Behaviors using /maintpage/* as the path pattern. The Target Origin should be the S3 maintenance assets origin.
Adding Custom Error Response mapping.
In the error code dropdown, select the HTTP code for which the maintenance page should be served. 502 gateway timeout is commonly used.
In the Response page path, enter /maintpage/5xx.html, replacing 5xx.html with a page that exists in S3.
The HTTP Response Code can be 200 or 502 (the same as the source origin response code).
Set up Storage Classes and PVCs in Kubernetes
Refer to steps here
Navigate to Kubernetes -> Storage -> Storage Class
Configure EFS parameter created at Step1 by clicking on EFS Parameter.
Here, we are configuring Kubernetes to use Storage Class created in Step 2 above, to create a Persistent Volume with 10Gi of storage capacity and ReadWriteMany access mode.
if you use K8s and PVCs to autoscale your storage groups and run out of space, simply adding new storage volumes may not resolve the issue. Instead, you must increase the size of the existing PVCs to accommodate your storage needs.
For guidance on how to perform volume expansion in Kubernetes, refer to the following resources:
Configure below in Volumes to create your application deployment using this PVC.
Support for AWS Timestream databases
DuploCloud supports the Amazon Timestream database in the DuploCloud Portal. AWS Timestream is a fast, scalable, and serverless time-series database service that makes it easier to store and analyze trillions of events per day at an accelerated speed.
Amazon Timestream automatically scales to adjust for capacity and performance, so you don’t have to manage the underlying infrastructure.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
From the RDS page, click the Timestream tab.
Click Add. The Add Timestream Database pane displays.
Enter the DatabaseName.
Select an Encryption Key, if required.
Click Submit. The Timestream database name displays on the Timestream tab.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
From the RDS page, click the Timestream tab.
Select the database from the Name column.
On the Tables tab, click Add. The Add Timestream Table pane displays.
Enter the Table Name and other necessary information to size and create your table.
Click Create.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
From the RDS page, click the Timestream tab.
Select the database from the Name column.
On the Timestream page, click the database's Action menu to modify the JSON code or launch the Console in AWS. You can also select the database name in the Name column and, from the Tables tab, click the table's Action menu to modify the JSON code or launch the Console in AWS or Delete a table.
You can manage RDS Snaphots from DuploCloud. Go to Navigate to Cloud Services -> Database and select the RDS tab. From the Actions menu, select Manage Snapshots.
The Manage Snapshots page shows the list of all manual and automated snapshots available within a Tenant. Additional details like owner and snapshot shared with the user are displayed. A user can also delete snapshots from this page.
You can view the Snapshot quota limits and numbers of snapshots used and available from this page.
Using IAM for secure log-ins to RDS databases
Authenticate to MySQL, PostgreSQL, Aurora MySQL, Aurora PostgreSQL, and MariaDB RDS instances using .
Using IAM for authenticating an RDS instance offers the following benefits:
Network traffic to and from the database is encrypted using Secure Socket Layer (SSL) or Transport Layer Security (TLS).
Centrally manage access to your database resources, instead of managing access individually for each DB instance.
For applications running on Amazon EC2 hosts, you can use profile credentials specific to your EC2 instance to access your database, instead of using a password, for greater security.
Use the System Config tab to enable IAM authentication before enabling it for a specific RDS instance.
In the DuploCloud Portal, navigate to Administrator -> System Settings.
Click the System Config tab. The Add Config pane displays.
From the Config Type list box, set Flags.
From the Key list box, select Enable RDS IAM auth.
From the Value list box, select True.
Click Submit. The configuration is displayed in the System Config tab.
You can also enable IAM for any MySQL, PostgreSQL, and MariaDB instance during RDS creation or by updating the RDS Settings after RDS creation.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
In the RDS tab, select the database for which you want to enable IAM.
Click the Actions menu and select RDS Settings -> Update IAM Auth. The Update IAM Auth pane displays.
Select Enable IAM Auth.
Click Update.
To download a token which you can use for IAM authentication:
In the DuploCloud Portal, navigate to Cloud Services -> Database.
In the RDS tab, select the database for which you want to enable IAM.
Click the Actions menu and select View -> Get DB Auth Token. The RDS Credentials window displays.
Click Close to dismiss the window.
Manage Performance Insights for RDS databases in DuploCloud
Performance Insights is an Amazon RDS feature that enables you to monitor and analyze the performance of your database. It provides key metrics and deep insights into database activity, helping you identify bottlenecks and optimize query performance. You can configure Performance Insights with DuploCloud when creating a new RDS instance and update them for an existing RDS instance .
When , complete the following steps:
Enable the Enable Performance Insights (Optional) option.
Set the retention period for Performance Insights data in the Performance Insights Retention in Days (Optional) field.
Select an encryption key to encrypt Performance Insights data in the Performance Insights Encryption (Optional) list box.
Select the Tenant from the Tenant list box.
In the DuploCloud Portal, navigate to Cloud Services -> Database and select the RDS tab.
Click on the RDS name in the NAME column.
From the Actions menu, select RDS Settings and then Update Performance Insights. The Update Performance Insights pane displays.
Select Enable Performance Insights.
In the Performance Insights Retention in Days field, enter a retention period (1–731 days).
From the Performance Insights Encryption list box, select an encryption key or select No Encryption.
Click Update to apply the changes.
Manage backup and restore for Relational Database Services (RDS)
Create a of an RDS.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
In the RDS tab, in the row containing your RDS instance, click the Actions menu icon ( ) and select Backup & Restore -> Create Snapshot.
Confirm the snapshot request. Once taken, the snapshot displays in the Snapshot tab.
You can restore available RDS snapshots to a specific point in time.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
Click the Snapshots tab.
Click the Actions menu and select Backup & Restore -> Restore to Point in Time. The Restore Point in Time pane displays.
In the Target Name field, append the RDS name to the prefilled TENANT_NAME prefix.
Select either the Last Restorable Time or Custom date and time option. If you select the Custom date and time option, specify the date and time in the format indicated.
Click Submit. Your selected RDS is restored to the point in time you specified.
can set backup retention periods in the DuploCloud Portal.
In the DuploCloud Portal, navigate to Administrator -> System Settings.
Select the System Config tab.
Click Add. The Config pane displays.
From the Config Type list box, select AppConfig.
From the Key list box, select RDS Automated Backup Retention days.
In the Value field, enter the number of days to retain the backup, from one (1) to thirty-five (35) days.
Click Submit. The System Configs area in the System Config tab is updated with the retention period you entered for the RDS Automated Backup Retention days key.
To update or skip the final snapshot, navigate to Cloud Services -> Database, and click the RDS tab. Select the name of the RDS database for which you want to update or skip the final snapshot.
From the Actions menu list box, select Backup & Restore -> Update Final Snapshot.
The Update Final Snapshot pane for the database displays. To skip the final snapshot upon database deletion, select Skip Final Snapshot. Click Update.
Administrator can configure parameters for RDS Parameter Group for DB Instances and Clusters from Administrator -> System Settings -> System Config.
Specify the Database Engines for auto creation of parameter groups. Administrator can set the supported parameters to override the values while creating RDS
Storage services included in DuploCloud for AWS
DuploCloud AWS Storage Services include:
You can also easily create and manage Kubernetes and within the DuploCloud Portal.
To create Hosts (Virtual Machines) see the .
Select the Enable IAM auth option when you .
In the RDS Credentials window, click the Copy Icon ( ) to copy the Endpoint, Username, and Password to your clipboard.
Once backups are available, you can restore them on the next instance creation when you .
In the RDS tab, select an RDS instance containing .
Mount an EFS in an EC2 instance using a script
If you want to connect an EFS to a Native Docker Service, for example, you can mount it in an EC2 instance.
Create a bash script, as in the example above, and replace nfs4 with your EFS endpoint. You can run the script below on an existing EC2 instance or run an EC2 user data script to configure the instance at first launch (bootstrapping).
In the DuploCloud Portal, edit the DuploCloud Service.
On the Edit Service page, click Next. The Advanced Options page displays.
On the Advanced Options page, in the Volumes field, enter the configuration YAML to mount the EFS endpoint as a volume.
You can create a Kinesis Stream. From the DuploCloud portal, navigate to Cloud Services -> Analytics and select the Kinesis Stream tab. Click the +Add button above the table. Refer to AWS DynamoDB User Guide to know more about the permissions.
Set a maximum instance size for an RDS
From the DuploCloud Portal, navigate to Administrator -> Systems Settings.
Select the System Config tab, and click Add. The Update Config AppConfig pane displays.
In the Config Type list box, select AppConfig.
From the Key list box, select RDS allowed max instance size.
From the Value list box, select the maximum instance size.
Click Submit. RDS instances will be limited to the maximum instance size configured.
Steps for sharing encrypted RDS databases in DuploCloud AWS
Sharing unencrypted databases to other accounts is very simple and straightforward. Sharing an encrypted database is slightly more difficult. Here we will go through the steps that need to be followed to share the encrypted database.
Create a managed key that can be used by both accounts. Share the managed key with the destination account.
Copy the existing snapshot in the source account, but encrypt it with the new key.
Share the new snapshot with the destination account.
In the destination account, make a copy of the shared snapshot encrypted with the destination account's key.
Add the Name tag to the new copy in the destination so the DuploCloud portal recognizes it.
Create a new database from the snapshot.
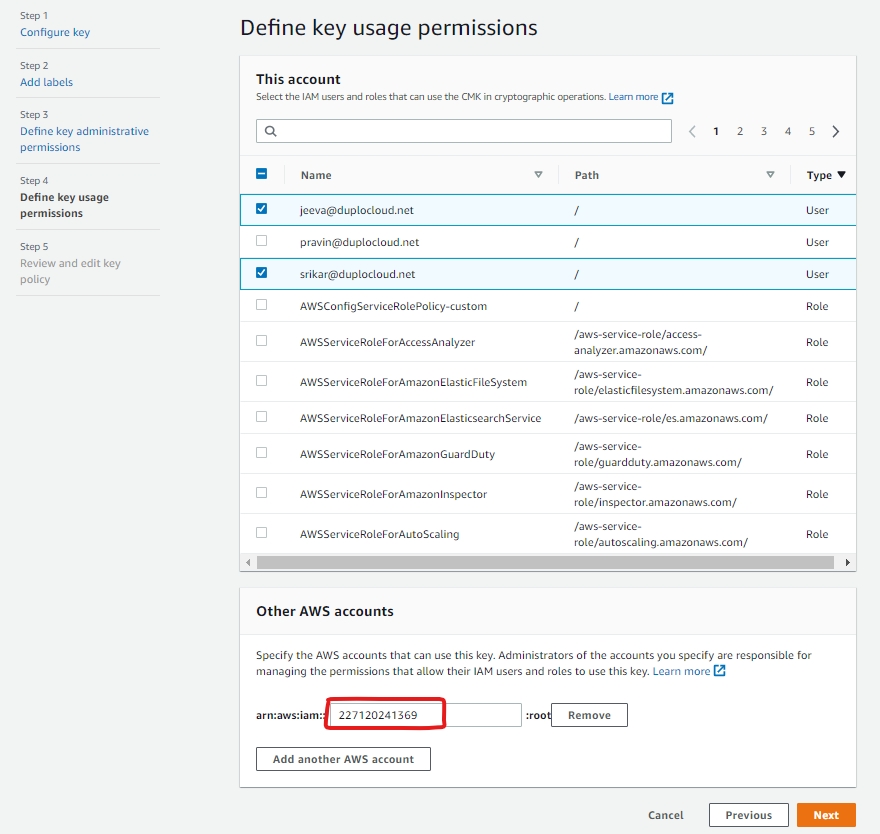
Create a new customer-managed key in AWS KMS. In the Define key usage permissions area provide the account id of the other account.
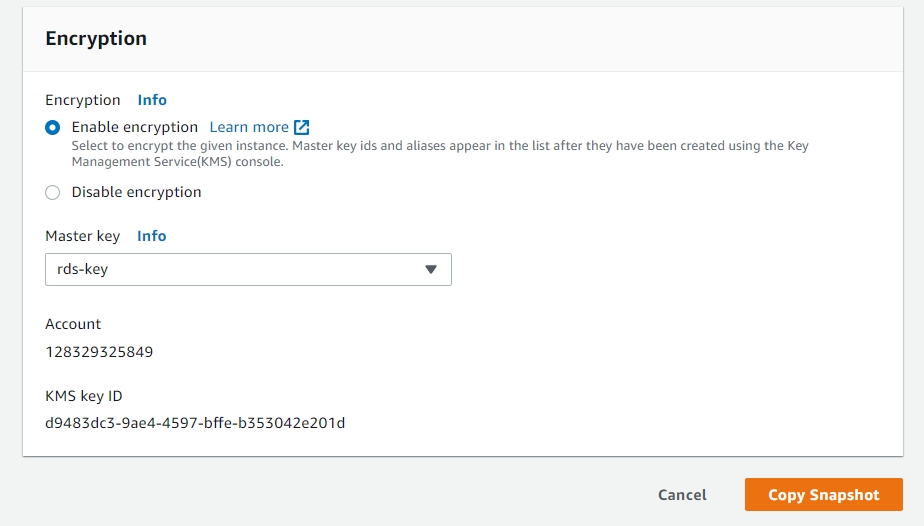
Once the key is created, navigate to Cloud Services -> Database and select the RDS tab. From the Actions menu, select Manage Snapshots. Select the snapshot, and click Copy Snapshot. In the encryption, use the key we created above.
Once the copied snapshot is ready, share the snapshot with another account by clicking Share snapshot and providing the destination account id.
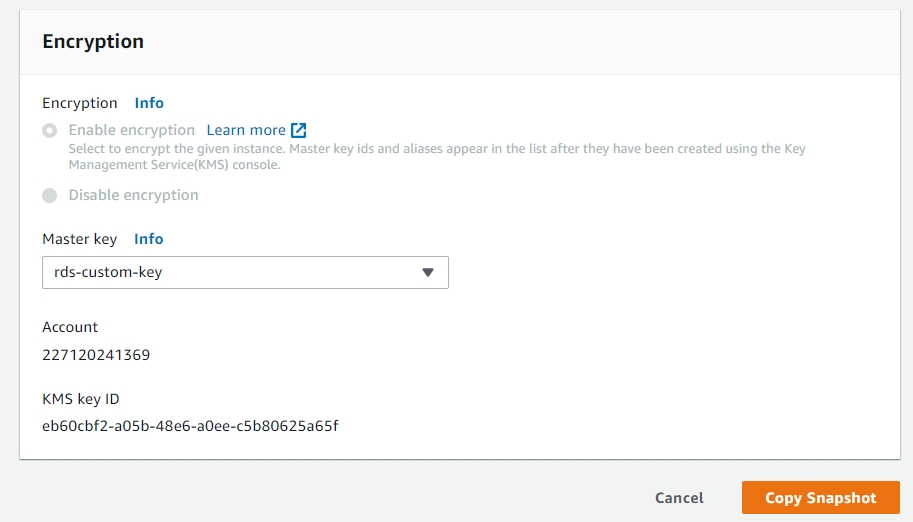
In the destination account, Navigate to Cloud Services -> Database and select the RDS tab. Select Shared with me. Select the shared snapshot and click copy-snapshot. Use the encryption key of the destination account, not the shared key.
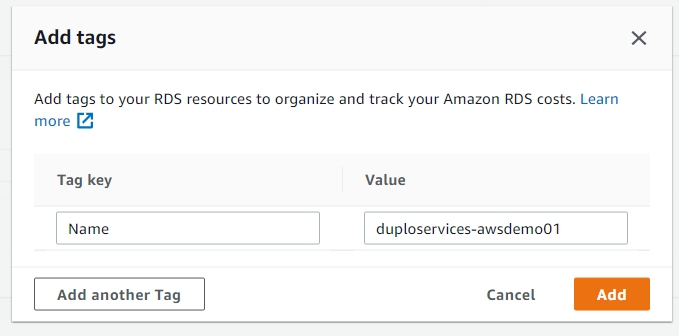
In the copied snapshot add a tag with Key as “Name” and Value as “duploservices-{tenantname}” where tenantname is the tenant where you want to launch an RDS with this snapshot.
Go to the DuploCloud portal and select the tenant. Navigate to Cloud Services -> Database and select the RDS tab. Click Add. Then give a name for the new database. In the snapshot select the new snapshot. Enter the instance type and click Submit. In a few minutes, the database will be created with the data from the snapshot. You must use the existing username and password to access the database.
Set a monitoring interval for an RDS database
Add or update a monitoring interval for an RDS database configuration.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
Click the RDS tab.
In the row for the RDS database that you want to update, click the ( ) icon in the Actions column, and select Update Monitoring Interval. The Update Monitoring Interval pane displays.
From the Monitoring Internal list box, select an interval, in seconds. To remove a previously set interval, select Disable.
Click Submit.
Turn logging on or off for an AWS RDS
You can enable or disable logging for an RDS database at any time, using the DuploCloud Portal.
To update logging for an RDS, you must select the Enable Logging option when you create the RDS.
In the DuploCloud Portal, navigate to Cloud Services -> Databases.
In the RDS tab, from the Name column, select the database for which you want to enable or disable logging.
Click the Actions menu, select RDS Settings, and then Update Logging. The Update Logging pane displays.
Select or deselect Enable Logging to turn logging on or off, respectively.
Click Update.
View the status of the EnableLogging attribute in the Details tab.
Create a read replica of your RDS database
Creating AWS RDS read replicas of your database helps you elastically scale your capacity to handle read-heavy workloads and ensure that your application can efficiently serve growing requests. Read replicas distribute read traffic across multiple instances, boosting performance by increasing aggregate read throughput and reducing the load on the primary database. Additionally, should the need arise, you can promote a read replica to a standalone database instance, enabling seamless failover and enhancing your overall database availability and resilience.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
Click the RDS tab.
Click on the name of the database you want to replicate in the NAME column.
From the Actions menu, select RDS Settings, and then Add Replica. The Add read replica to: DATABASE pane displays.
In the Read Replica Name field, provide a name for the replica (the Tenant name is prefixed automatically).
From the Instance Size list box, choose a size that meets or exceeds the specifications of the database you are replicating.
Click Create. Your replica displays on the RDS tab with a status of Submitted. When the replica is ready for use, the status changes to Available.
Transforming a read replica into a standalone primary instance allows it to accept write operations and maintain data integrity without relying on the original primary. This enhances database availability and efficient scaling. DuploCloud supports promoting read replicas for PostgreSQL, MySQL, and MariaDB databases.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
Select the RDS tab.
Click on the name of the database you want to promote from the NAME column.
In the Actions menu, select RDS Settings, and then Promote Replica.
Click Confirm in the confirmation dialog box. The promoted replica stops replicating from the primary instance and becomes a standalone database that can accept write operations.
Create and connect to an RDS database instance
Create, configure, and manage RDS instances directly from the DuploCloud Portal.
DuploCloud supports the following RDS databases in AWS:
MySQL
PostgreSQL
MariaDB
Microsoft SQL-Express
Microsoft SQL-Web
Microsoft SQL-Standard
Aurora MySQL
Aurora MySQL Serverless
Aurora PostgreSQL
Aurora PostgreSQL Serverless
*Support for Aurora Serverless V1 database engines has been deprecated. Do not create V1 engines when using Terraform.
When upgrading RDS versions, use the AWS Console and see your Cloud Provider for compatibility requirements. Note that while versions 5.7.40, 5.7.41, and 5.7.42 cannot be upgraded to version 8.0.28, you can upgrade them to version 8.0.32 and higher.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
Click Add. The Create a RDS page displays.
Complete the following fields:
RDS Name: Enter a unique name for the RDS instance. DuploCloud suggests using the Tenant name as a prefix, e.g., tenantname-db.
Create from Snapshot (Optional): Select an existing snapshot to restore from if applicable.
RDS Engine: Choose the database engine (e.g., MySQL, PostgreSQL, MariaDB).
RDS Engine Version: Select the engine version.
Encryption Key (Optional): Select an encryption key if needed for encryption at rest.
Storage Type (Optional): Choose the storage type (e.g., General Purpose SSD, Provisioned IOPS).
Storage Size in GB (Optional): Specify the storage size in GiB. (Minimum: 20 GiB, Maximum: 65,536 GiB.)
RDS Instance Size: Choose an instance type based on performance needs.
DB Parameter Group (Optional): Select a custom database parameter group if needed.
DB Subnet Group (Optional): Choose a subnet group for the database network configuration.
Backup Retention Period in Days: Enter a retention period between 1 and 35 days.
User Name: Enter the database username. (Required)
User Password: Enter a secure password for the database. (Required)
Optionally, select Enable Performance Insights.
Performance Insights Retention in Days (Optional): Enter the retention period for Performance Insights data. (Default: 7 days, Maximum: 731 days.)
Performance Insights Encryption (Optional): Select an encryption key for encrypting Performance Insights data. (If not specified, AWS will use the default key.)
Enable Additional Features (Optional):
Enable IAM Auth
Store Credentials in Secrets Manager
Enable Multi-AZ
Enable Logging
Click Create to provision the RDS database.
You can create Aurora Serverless V2 Databases by selecting Aurora-MySql-Serverless-V2 or Aurora-PostgreSql-Serverless-V2 from the RDS Database Engine list box. Select the RDS Engine Version compatible with Aurora Serverless v2. The RDS Instance Size of db.serverless applies to both engines.
Create a DB subnet group in AWS consisting only of public subnets from your VPC.
In the DuploCloud Portal, navigate to Cloud Services -> Databases
Select the RDS tab, and click Add. The Create a RDS page displays.
In the DB Subnet Group list box select the public DB subnet group you created in AWS.
Complete the remaining fields according to your requirements.
Click Create. The publicly available RDS database is created.
To create a public RDS database, you much first create a DB subnet group in AWS consisting only of public subnets from your VPC. Then follow the steps above to create an RDS database, selecting the DB subnet group you created from the DB Subnet Group list box.
The DB subnet group created in AWS must only contain public subnets from your VPC. This configuration is crucial for making the database public.
Once you create the database, select it and use the Instances tab to view the endpoint and credentials. Use the Endpoints and credentials to connect to the database from your application running in an EC2 instance. The database is only accessible from inside the EC2 instance in the current Tenant, including the containers running within.
For databases you intend to make publicly available, ensure proper security measures, including broad accessibility, are in place to protect your data.
Pass the endpoint, name, and credentials to your application using environment variables for maximum security.
In the DuploCloud Portal, navigate to Cloud Services -> Database and select the RDS tab.
Click on the RDS name in the NAME column.
From the Actions menu, select RDS Settings and then Update Performance Insights. The Update Performance Insights pane displays.
Select Enable Performance Insights.
In the Performance Insights Retention in Days field, enter a retention period (1–731 days).
From the Performance Insights Encryption list box, select an encryption key or select No Encryption.
Click Update to apply the changes.
Create a read replica of an Aurora database
Aurora database replica setup is slightly different from adding an RDS read replica.
In the DuploCloud Portal, navigate to Cloud Services -> Database.
In the row of the RDS for which you want to add an Aurora read replica, click the ( ) icon, select RDS Settings, and then Add Replica. The Add Replica pane displays.
Follow one of these procedures to complete the serverless and MySQL replicas setup.
In the Add Replica pane, enter a name for the Serverless replica in the Replica Name field.
In the RDS Engine field, select the Aurora RDS Serverless engine you want the replica to use.
Specify Min Capacity (ACUs) and Max Capacity (ACUs).
From the RDS Instance Size list box, select the appropriate instance size.
Click Save. The replica is created with a Reader role and displayed in the RDS tab.
To modify instance sizes for an existing Aurora Serverless replica:
In the DuploCloud Portal, navigate to Cloud Services -> Database and, in the RDS tab, locate the read replica you want to update in the Name column.
From the RDS Instance Size list box, select the appropriate instance size.
Click Save.
In the Add Replica pane, enter a name for the MySQL replica in the Replica Name field.
From the RDS Instance Size list box, select the appropriate instance size.
From the Availability Zone list box, select an availability zone
Click Save. The replica is created with a Reader role and displayed in the RDS tab.
Use AWS Elastic Container Registry with DuploCloud
Amazon Elastic Container Registry (ECR) is a fully managed Docker container registry that allows users to easily store, manage, and deploy container images within AWS. ECR integrates seamlessly with Amazon ECS, EKS, and other AWS services to provide secure and scalable container image storage. Users can push, pull, and manage container images with built-in security features like encryption at rest and access control via AWS IAM.
In the DuploCloud Portal, navigate to Cloud Services -> Storage.
Click the ECR Repository tab. The ECR Repository page displays.
Click Add. The Create an ECR Repository page displays.
In the ECR Repository Name field, enter the ECR Repository Name.
Click Create.
Login to ECR
Tag the images you have built.
Push the images to the ECR Repository that you created.
Refer to the AWS Documentation for more details about uploading Container Images.
Select the Tenant from the Tenant list box.
Navigate to Cloud Services -> Storage in the DuploCloud Portal.
Select the ECR Repository tab.
Select Update Settings. The Update ECR Repository Settings pane displays.
Enable or disable Image Tag Immutability and Scan Image On Push settings as needed.
Click Update. The ECR settings are updated
If you no longer need an ECR repository used for storing Lambda container images, you can delete it from DuploCloud.
Select the Tenant from the Tenant list box.
Navigate to Cloud Services -> Storage in the DuploCloud Portal.
Select the ECR Repository tab.
Select Delete or Force Delete:
Delete: If the repository contains any images, you will need to manually remove them before you can delete the repository.
Force Delete: This option immediately removes the repository and all of its contents (container images) without needing to empty the repository first.
Create an Amazon Elastic File System (EFS) from the DuploCloud Portal
Amazon Elastic File System (Amazon EFS) is a scalable, fully managed file storage service. It offers a simple and scalable file storage solution for use with AWS cloud services and on-premises resources. It is designed to provide shared file storage for multiple instances, enabling concurrent access, as well.
See the for more information.
Before you create an EFS, you must configure the EFS Volume Controller for your Infrastructure.
In the DuploCloud portal, navigate to Administrator -> Infrastructure. The Infrastructure page displays.
Select your Infrastructure from the Name column.
Click the Settings tab.
Click Add. The Infra - Set Custom Data pane displays.
From the Settings Name list box, select Enable EFS Volume Controller.
Select Enable.
Click Set.
In the Settings tab, your configuration Enable EFS Volume Controller is set to true.
In the DuploClod Portal, navigate to Cloud Services -> Storage.
Click the EFS tab.
Click Add. The Add Elastic File System page displays.
In the Name field, enter a name for the EFS you want to create.
In the Creation Token field, enter a string of up to 64 ASCII characters.
From the Performance Mode list box, select General or Max I/O. Select General for most file systems. Selecting Max I/O allows scaling to higher levels of aggregate throughput and operations per second with a tradeoff of slightly higher latencies for most file operations. You can not change this setting after the file system has been created.
From the Throughput Mode list box, select Bursting or Provisioned. If you select Provisioned, you must also set a value from 1 to 1024 for Provisioned Throughput (in MiB). After you create the file system, you can decrease the file system's throughput in Provisioned mode or change between the throughput modes, as long as more than 24 hours have passed since the last decrease in throughput or throughput mode change.
Change other defaults as needed as click Create. The EFS is created and displayed in the EFS tab. Select the EFS from the Name column and view the configuration in the Details tab.
Information about EFS Mount Targets and Access Points is available in their respective tabs.
If you want to disable an EFS Lifecycle Management Policy that you previously created, you must do so in the AWS Portal. You can not disable a Lifecycle Management Policy by using the DuploCloud portal.
In the DuploClod Portal, navigate to Cloud Services -> Storage.
Click the EFS tab.
Select the EFS from the Name column. The EFS page displays.
From the Actions menu, select Update Lifecycle Policies. The Update EFS Lifecycle Policies pane displays.
From the Transition to IA list box, select the time duration (in days) to elapse before transitioning files to the IA storage class.
Optionally, select Transition to Primary Storage Class, if appropriate.
Click Submit. The EFS Lifecycle Policies are updated and can be viewed in the Lifecycle Policies tab.
Enabling IoT for a Tenant, creating Things and supporting certificates
Connect and manage billions of devices with AWS IoT, per Tenant. Collect, store, and analyze IoT data for industrial, consumer, commercial, and automotive workloads within DuploCloud.
Use to provision devices in your IoT.
In the DuploCloud Portal, navigate to Administrator -> Tenants.
Select your Tenant in the Name column.
Click the Settings tab.
Click Add. The Add Tenant Feature pane displays.
From the Select Feature list box, select Enable AWS IoT and Enable.
Click Add. It takes approximately five minutes to enable IoT.
Navigate to Cloud Services -> IoT. The IoT Things page displays.
In the DuploCloud Portal, navigate to Cloud Services -> IoT.
Click the Things tab.
Click Add. The Create an IoT Thing pane displays.
In the editable portion of the Name field, enter a Thing name.
From the IoT Certificate list box, select an IoT Certificate.
From the IoT Thing Type list box, select the Thing type that you want to create.
In the Attributes field, add Thing Attributes in quotes, separated by a comma (,).
Click Create. Your IoT Thing is created and displayed.
Select the Thing to view Details and IoT Principals (certificate information) for the Thing. Use the Action menu to Edit or Delete the Thing, Attach IoT Certificate, and Download Device Package.
In the DuploCloud Portal, navigate to Cloud Services -> IoT.
Click the Things tab.
Select the Thing to which you want to attach a certificate from the Name column.
Click the Actions menu and select Attach IoT Certificate. The Attach an IoT Certificate pane displays.
From the IoT Certificate list box, select an IoT certificate to attach to the Thing.
Click Attach.
In the DuploCloud Portal, navigate to Cloud Services -> IoT.
Click the Things tab.
Select the Thing to which you want to attach a certificate from the Name column.
Click the Actions menu and select Download Device Package. The Download IoT Device Package window displays.
From the IoT Certificate list box, select the IoT certificate associated with the Thing's Device Package.
Click Download.
Add, update, or manage an IoT certificate with the following procedures.
In the DuploCloud Portal, navigate to Cloud Services -> IoT.
Click the Certificates tab.
Click Add. The Create an IoT Certificate pane displays.
Select Activate the Certificate and click Create. The certificate displays.
In the DuploCloud Portal, navigate to Cloud Services -> IoT.
Click the Certificates tab. The available certificates are displayed and listed by ID.
From the Status list box, select the new status of the certificate.
Click Update.
In the DuploCloud Portal, navigate to Cloud Services -> IoT.
Click the Certificates tab. Available certificates are displayed and listed by ID.
Select Console. The AWS Console launches so that you can manage your certificate using AWS.
Topic Rules are SQL-based rules that select data from message payloads and send data to other services, such as Amazon S3, Amazon DynamoDB, and AWS Lambda. Define a Rule to invoke a Lambda function when invoking an AWS or third-party service.
In the DuploCloud Portal, navigate to Cloud Services -> IoT.
Click the Topic Rules tab.
Click Add. The Add Topic Rules page displays.
In the Name field, enter a Topic Rule name.
Add a meaningful description of what the rule does in the Description field.
Define the rule by completing the fields in the AWS IoT SQL and AWS IoT SQL Version areas. Select Define an Error Action if the rule pertains to error management.
Click Create. Your rule is defined and displayed in the Topic Rules tab.
View the details of a rule by selecting the rule from the Topic Rules tab Name column. The Details tab displays the rule description. The Actions tab displays the SQL-based rule(s).
Collect and display real-time event data in AWS with DuploCloud
Amazon collects and visualizes real-time logs, metrics, and event data in automated dashboards to streamline your cloud infrastructure and application maintenance.
By default, the metrics for a resource are available on the Metrics page in DuploCloud. Some metrics, however, need agents to be installed in the system to collect the information, such as .
DuploCloud provides a way to automatically install these agents on all the hosts whenever they are provisioned. For more information, refer to the DuploCloud Security White Paper PCI and HIPAA Compliance with DuploCloud, and read the General section, Agent Models, to learn about installing agents for compliance controls and security frameworks
In the DuploCloud Portal, navigate to Cloud Services -> App Integration.
Click the EventBridge tab.
Click Add. The Add EventBridge Rule page displays; or to update an existing rule, select the menu ( ) icon in the Actions column for the rule you want to update, and click Update. The Update EventBridge Rule page displays.
In the Rule Name field, specify or change the rule name.
In the Description field, specify or change the rule description.
In the Schedule Expression field, enter or edit the interval for which you want this rule to run. Use the format: rate(x interval), where x is a numeric value and interval is seconds, minutes, hours, or days. Ensure that you include a blank space between the numeric value x and the interval.
From the State list box, select Enabled.
Click Submit. The rule is displayed in the EventBridge tab.
You define targets and associated types in DuploCloud. DuploCloud supports types ECS Task and Lambda.
In the DuploCloud Portal, navigate to Cloud Services -> App Integration.
Click the EventBridge tab. The rules you defined are displayed.
In the Target tab, click Add. The Add Rule Target page displays.
In the Target tab, click Add. The Add Rule Target page displays.
In the Name field, enter a target name.
From the Target Type list box, select a target type.
From the Task Definition Family list box, select a task definition family.
In the Task Version field, enter a numeric version number.
Click Submit. The Target you added is displayed in the Target tab.
Create a Kafka Cluster for real-time streaming data pipelines and apps
Apache Kafka (Kafka) is an open-source, distributed streaming platform that enables the development of real-time, event-driven applications. It is used to build real-time streaming data pipelines and real-time streaming applications.
A data pipeline reliably processes and moves data from one system to another, and a streaming application is an application that consumes streams of data. Streaming platforms enable developers to build applications that continuously consume and process streams at high speeds, with a high level of accuracy.
When creating a Kafka Cluster in DuploCloud, if you want to select a Cluster Configuration and Configuration Revision, you must add the configuration or revision in the AWS console before creating the DuploCloud Kafka cluster.
For complete documentation on Apache Kafka, see the .
In the DuploCloud Portal, navigate to Cloud Services -> Analytics.
Click the Kafka tab.
Click Add. The Create a Kafka Cluster pane displays.
Enter a Kafka Cluster Name.
From the field list boxes, select a Version of Kafka, the Size of the cluster you want to create, the Volume size in gigabytes, and the Transit Encryption mode.
Optionally, select Availability Zones or Number of BrokerNodes. You must specify a minimum of two (2) Availability Zones zones.
Optionally, select a Cluster Configuration and Configuration Revision when creating a Kafka Cluster in DuploCloud. The Cluster Configuration and Configuration Revision list boxes are prepopulated with configurations and revisions previously defined in the AWS Portal.
Click Submit. The cluster is created and displayed as Active in the Kafka tab. It may take up to half an hour to create the cluster.
View Kafka Clusters by navigating to Cloud Services -> Analytics in the DuploCloud Portal and selecting the Kafka tab.
In the DuploCloud Portal, navigate to Cloud Services -> Analytics.
Click the Kafka tab.
Select the Kafka Cluster with Active Status from the Name column. The Kafka Cluster page displays.
Click the Actions menu and select Change Configuration. The Change Cluster Configuration pane displays.
From the Cluster Configuration list box, select the new cluster configuration.
From the Configuration Revision list box, select the revision of the new cluster configuration.
Click Submit. The configuration change is displayed on the Kafka Cluster page
Click the ( ) icon in the Actions column and select Update Instance Size. The Update Instance Size pane displays.
In the row of the ECR repository you want to delete, click the menu icon ().
In the row of the ECR repository you want to delete, click the menu icon ().
Max I/O mode is not supported on file systems using .
You can update the policies for EFS Lifecycle management in the DuploCloud Portal. See the for more information.
if needed.
In the row for the certificate you want to update, click the Actions menu ( ) and select Edit. The Update an IoT Certificate pane displays.
In the row for the certificate you want to update, click the menu () icon in the Actions column.
To learn more about IoT Topic Rules and how you define and manage them, see the .
In the Topic Rules tab, edit a Topic Rule by clicking the Actions menu ( ) in the row listing your Topic Rule Name, and selecting Edit.
An EventBridge is a resource or endpoint to which EventBridge sends an when the event matches the event pattern defined for a . The rule processes data and sends pertinent information to the target. To deliver event data to a target, EventBridge needs permission to access the target resource. You can define up to five targets for each rule.
.
AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals. With AWS Data Pipeline, you can regularly access your data where it’s stored, transform and process it at scale, and efficiently transfer the results to AWS services such as Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR.
AWS Data Pipeline helps you easily create complex data processing workloads that are fault tolerant, repeatable, and highly available. You don’t have to worry about ensuring resource availability, managing inter-task dependencies, retrying transient failures or timeouts in individual tasks, or creating a failure notification system. AWS Data Pipeline also allows you to move and process data that was previously locked up in on-premises data silos.
A data pipeline can be created using any of the following ways:
Using DuploCloud UI
Using an exported template from AWS console
Cloning an existing template
Proceed to Cloud Services → Analytics -> Data Pipeline. Click on +Add button.
Enter relevant information on the form. Click Generate button. The form includes information like - name, description, s3 log folder, cron schedule details, EMR resources, EMR steps, etc.
Review generated JSON, and make any further changes to generated JSON
Proceed to Cloud Services → Analytics -> Data Pipeline. Click on +Add button. Click 'Import Pipeline Template'
In AWS console Proceed to Data Pipeline -> Choose Existing Data Pipeline -> Click Edit -> Click Export. Please review generated JSON, and make any further changes to generated JSON. Click Submit.
Copy previously exported template from the form. Please do any additional changes (such as schedule frequency, EMR steps). Click Submit to save the Data Pipeline.
Existing Data Pipelines can be cloned in List View or Details View.
To get JIT (Just In Time) access to appropriate AWS console, click on Data Pipeline, EMR Console, EMR Jupyter Console. Click **** row level menu actions to manage the Data Pipeline. e.g. Clone, Edit, Export, Delete etc.
Use Details view to update Data Pipeline. Use JIT (Just In Time) access to AWS console. Check Errors and warnings.
There are two types of Data Pipeline templates:
Exported template in AWS console
Exported template in DuploCloud UI
Support for Kubernetes Probes
Liveness, Readiness, and Startup probes are well-known methods to detect Pod health in Kubernetes. They are used in regular uptime monitoring and enable initial startup health that allows rolling deploys of new service updates.
The example below will define Liveness, Readiness, and Startup probes to one service deployment.
While creating a deployment, provide the below configuration to set up probes for your service.
In addition to the httpGet example, TCP Probes can be configured from the Other Container Config field:
Run big data applications with open-source frameworks without managing clusters and servers
Amazon EMR Serverless is a serverless option in Amazon EMR that makes it easy for data analysts and engineers to run open-source big data analytics frameworks without configuring, managing, and scaling clusters or servers. You get all the features and benefits of Amazon EMR without needing experts to plan and manage clusters.
In this procedure, we create an EMR studio, create and clone a Spark application, then create and clone a Spark job to run the application with EMR Serverless.
DuploCloud EMR Serverless supports Hive, Spark, and custom ECR images.
To create EMR Serverless applications you first need to create an EMR studio.
In the DuploCloud Portal, navigate to Cloud Services -> Analytics.
Click the EMR Serverless tab.
Click EMR Studio.
Click Add. The Add EMR Studio pane displays.
Enter a Description of the Studio for reference.
Select an S3 Bucket that you previously defined from the Logs Default S3 Bucket list box.
Optionally, in the Logs Default S3 Folder field, specify the path to which logs are written.
Click Create. The EMR Studio is created and displayed.
Select the EMR Studio name in the Name column. The EMR Studio page displays. View the Details of the EMR Serverless Studio.
Navigate to the EMR Serverless tab and click the menu () icon in the Actions column. Use the Actions Menu to delete the studio if needed, as well as to view the studio in the AWS Console.
Now that the EMR Studio exists, you create an application to run analytics with it.
The DuploCloud Portal supports Hive and Spark applications. In this example, we create a Spark Application.
In the EMR Serverless tab, click Add. A configuration wizard launches with five steps for you to complete.
Enter the EMR Serverless Application Name (app1, in this example) and the EMR Release Label in the Basics step. DuploCloud prepends the string DUPLOSERVICES-TENANT_NAME to your chosen application name, where TENANT_NAME is your Tenant's name. Click Next.
Accept the defaults for the Capacity, Limits, and Configure pages by clicking Next on each page until you reach the Confirm page.
On the Confirm page, click Submit. Your created application instance (DUPLOSERVICES-DEFAULT-APP1, in this example) is displayed in the EMR Serverless tab with the State of CREATED.
Before you begin to create a job to run the application, clone an instance of it to run.
Make any desired changes while advancing through the Basics, Capacity, Limits, and Configure steps, clicking Next to advance the wizard to the next page. DuploCloud gives your cloned app a unique generated name by default (app1-c-833, in this example).
On the Confirm page, click Submit. In the EMR Serverless tab, you should now have two application instances in the CREATED State: your original application instance (DUPLOSERVICES-DEFAULT-APP1) and the cloned application instance (DUPLOSERVICES-DEFAULT-APP1-C-833).
You have created and cloned the Spark application. Now you must create and clone a job to run it in EMR Serverless. In this example, we create a Spark job.
Select the application instance that you previously cloned. This instance (DUPLOSERVICES-DEFAULT-APP1-C-833, in this example) has a STATE of CREATED.
Click Add. The configuration wizard launches.
In the Basics step, enter the EMR Serverless RunJob Name (jobfromcloneapp, in this example).
Click Next.
In the Job details step, select a previously-defined Spark Script S3 Bucket.
In the Spark Script S3 Bucket File field, enter a path to define where your scripts are stored.
Optionally, in the Spark Scripts field, you can specify an array of arguments passed to your JAR or Python script. Each argument in the array must be separated by a comma (,). In the example below, a single argument of "40000" is entered.
Optionally, in the Spark Submit Parameters field, you can specify Spark --conf parameters. See the example below.
Click Next.
Make any desired changes in the Configure step and click Next to advance the wizard to the Confirm page.
On the Confirm page, click Submit. In the Run Jobs tab for your cloned application, your job JOBFROMCLONEAPP displays.
Observe the status of your jobs and makes changes, if needed. In this example, we monitor the Spark jobs created and cloned in this procedure.
In the DuploCloud Portal, navigate to Cloud Services -> Analytics.
Click the EMR Serverless tab.
Select the application instance that you want to monitor. The Run Jobs tab displays run jobs connected to the application instance and each job's STATE.
Using the Actions menu, you can view the Console, Start, Stop, Edit, Clone or Delete jobs. You can also click the Details tab to view configuration details.
Create an OpenSearch domain from the DuploCloud portal
Navigate to Cloud Services -> Analytics, select the OpenSearch tab, and click the Add button. The Add OpenSearch Domain page displays.
In the Domain Name field, create a name for the OpenSearch domain.
In the OpenSearch Version field, select the OpenSearch version you are using.
Select your needed instance size from the Data Instance Size list box.
Enter the the instance count in the Data Instance Count field, and choose the correct zone(s) from the Zone list box.
Optionally, enter a key in the Encryption Key (Optional) field.
In the Storage (In Gb) field, enter the amount of storage needed.
If needed, select a Master Instance Count and Master Instance Size.
Use the toggle switches to enable encryption options (Require SSL/HTTPS, Use Latest TLS Cipher, or Enable Node-to-Node Encryption), if needed.
Optionally, use the toggle switch to Enable UltraWarm data nodes (nodes that are optimized for storing large volumes of data cost-effectively). When this option is enabled, additional fields display. Select a Warm Instance type, enter Number of warm data nodes, and Enable Cold Storage as your application requires.
Click Submit. The OpenSearch domain is created.
To create an OpenSearch without EBS storage, follow the steps to create an OpenSearch domain. In the Data Instance Size list box, select Other, and enter a storage type instance, For example, i3.2xlarge.search. Complete the remaining steps and click Submit.
See the Logging documentation.
Using Container Images to configure Lambda
Lambda container images allow you to package and deploy Lambda functions as Docker container images. By using container images, you can include custom libraries, runtimes, and dependencies that are not available in the standard Lambda execution environment. The process involves building the container image, storing it in Amazon Elastic Container Registry (ECR), and configuring Lambda to use the image for function execution.
Create and Build your Lambda code using DockerFile. Refer to the AWS documentation for detailed instructions on how to build and test container Images.
To use container images with Lambda, your images must be stored in Amazon Elastic Container Registry (ECR). ECR provides a fully managed service to store your container images, which Lambda pulls to run your functions.
For detailed instructions on how to configure and use ECR with Lambda, refer to the DuploCloud ECR documentation.
In the DuploCloud Portal, navigate to Cloud Services -> Serverless.
Click the Lambda tab. The Lambda Function page displays.
Click Add. The Create a Lambda Function page displays.
In the Name field, enter the name of your Lambda Function.
In the Description field, enter a useful description of the function.
From the Package Type list box, select Image. For type Zip, see the Lambda Functions topic.
Optionally, enter an Image Configuration. Refer to the informational ToolTip ( ) for examples.
In the Image URL field, enter the URL of the image.
Click Submit. The Lambda function is created.
On the Lambda Function page, from the Name column, select the function you created.
From the Actions menu, click Console. You are redirected to the AWS Console.
Test the function using the AWS Console.
Package code libraries for sharing with Lambda Functions
A Lambda Layer is a Zip archive that can contain additional code or other content. A Lambda Layer may contain libraries, a custom runtime, data, or configuration files.
Lambda Layers provide a convenient and effective way to package code libraries for sharing with Lambda functions in your account. Using layers can help reduce the size of uploaded archives and make it faster to deploy your code.
You must add a Key/Value pair in the DuploCloud Portal's System Config settings to display Lambda Layers in DuploCloud.
In the DuploCloud Portal, navigate to Administrator -> System Settings.
Click the System Config tab.
Click Add. The Add Config pane displays.
From the Config Type list box, select Other. The Other Config Type field displays.
In the Other Config Type field, enter AppConfig.
In the Key field, enter ListAllLambdaLayers.
In the Value field, enter True.
Click Submit. The Key/Value pair is displayed in the System Config tab.
After you set ListAllLambdaLayers to True:
Layer names prefixed with DUPLO- display for all Tenants in the DuploCloud Portal.
Layer names prefixed with DUPLOSERVICES- display in the appropriate Tenant.
Before you add a Lambda Layer, you must have defined at least one Lambda Function.
In the DuploCloud Portal, navigate to Cloud Services -> Serverless.
In the Lambda tab, select the Lambda Function to which you want to add Lambda Layers.
Click the Actions menu and select Edit. The Edit Lambda Function page displays.
In the Layers area, click the + button. The Add Lambda Layer pane displays.
From the Layer list box, select the Lambda Layer to add.
From the Version list box, select the layer version.
Click Add Layer. The layer you added is displayed in the Layers area of the Edit Lambda Function page.
Use Lambda to deploy serverless functions in DuploCloud
Lambda is a serverless computing platform provided by AWS that allows you to run code without provisioning or managing servers. It enables you to build and run applications in response to events or triggers from Lambda Functions.
Lambda Functions are event-driven and designed to perform small, specific tasks or functions. They can be written in supported programming languages such as Python, JavaScript (Node.js), Java, C#, PowerShell, or Ruby. Once you create a Lambda function, you can configure it to respond to various types of events, such as changes in data stored in an Amazon S3 bucket, updates in an Amazon DynamoDB table, incoming HTTP requests via Amazon API Gateway, or custom events triggered by other AWS services.
Using Lambda, you write your code and upload it to AWS. Lambda executes and scales the code as needed, abstracting away the underlying infrastructure, and allowing you to focus on writing the actual business logic of your application. Lambda Functions are the principal resource of the Lambda serverless platform.
Use CI/CD GitHub Actions to update Lambda functions with images or S3 bucket updates.
In a Zip file, the Lambda Function code resides at the root of the package. If you are using a virtual environment, all dependencies should be packaged.
Refer to the AWS documentation for detailed instructions on how to generate the package, using tools such as Zappa and Serverless.
Use JIT to access the AWS Console.
Upload the Zip package in the AWS Console.
In the DuploCloud Portal, navigate to Cloud Services -> Serverless.
Click the Lambda tab. The Lambda Function page displays.
Click Add. The Create a Lambda Function page displays.
In the Name field, enter the name of your Lambda Function.
In the Description field, enter a useful description of the function.
From the Package Type list box, select Zip. For type Image, see the Configure Lambda with Container Images topic.
In the Runtime field, enter the runtime for your programming language.
From the the Architecture list box, select the correct Lambda Architecture.
To allocate a temporary file share, enter the value in megabytes (MB) in the Ephemeral Storage field. The minimum value is 512; the maximum value is 10240.
In the Function Handler field, enter the method name that Lambda calls to execute your function.
In the S3 Bucket list box, select an existing S3 bucket.
In the Function Package field, enter the name of the Zip package containing your Lambda Function.
DuploCloud Lambda supports Java-based function packages, such as HelloWorld.jar, stored in S3. Ensure that the JAR file is uploaded to the S3 bucket before configuring the Lambda function.
In the Dead Letter Queue list box, select an Amazon Simple Queue Service (SQS) queue or Amazon Simple Notification Service (SNS) topic.
Click Submit. The Lambda Function is created.
On the Lambda Function page, from the Name column, select the function you created.
From the Actions menu, click Console. You are redirected to the AWS Console.
Test the function using the AWS Console.
DuploCloud enables you to create a classic micro-services-based architecture where your Lambda function integrates with any resource within your Tenant, such as S3 Buckets, Dynamo database instances, RDS database instances, or Docker-based microservices. DuploCloud implicitly enables the Lambda function to communicate with other resources but blocks any communication outside the Tenant, except Elastic Load Balancers (ELB).
To set up a trigger or event source, create the resource in the DuploCloud Portal. You can then trigger directly from the resource to the Lambda function in the AWS console menu of your Lambda function. Resources can be S3 Buckets, API gateways, DynamoDB database instances, and so on.
Passing secrets to a Lambda function can be done in much the same manner as passing secrets to a Docker-based service using Environmental Variables. For example, you can create a relational database from the Cloud Services -> Database -> RDS menu in DuploCloud, providing a Username and Password. In the Lambda menu, supply the same credentials. No secrets need to be stored in an AWS Key Vault, a Git repository, and so on.
To update the code for the Lambda function:
Create a new Zip package with a different name and upload it in the S3 bucket.
Select the Lambda Function (with the updated S3 Bucket). From the Actions menu, click Edit.
Enter the updated Name of the Lambda Function.
Use the Image Configuration field to update an additional configuration parameter.
Click Submit.
Create an S3 bucket for AWS storage
Amazon Simple Storage Service (Amazon S3) is an object-storage service offering scalability, data availability, security, and performance. You can store and protect any data for data lakes, cloud-native applications, and mobile apps. Read more about S3 and its capabilities here.
To configure an S3 bucket for auditing, see the Auditing topic.
When creating an S3 bucket using the duplocloud_s3_bucket resource in Terraform, a unique identifier is appended to the bucket name to ensure global uniqueness, as AWS requires. This identifier is the AWS account ID, and a prefix with the tenant name (duploservices-<tenant_name>-) is also added. Additionally, for configuring access logs, the default S3 bucket naming convention follows duplo-<INFRA-NAME>-awslogs-<ACCOUNTNUMBER>, facilitating streamlined log management across services and ingress configurations. DuploCloud automatically adds a prefix and a suffix to bucket names to minimize naming conflicts in the global S3 namespace.
In the DuploCloud Portal, navigate to Cloud Services -> Storage.
Click the S3 tab.
Click Add. The Create an S3 Bucket pane displays.
In the Name field, enter a name for the S3 bucket.
In the Region list box, select the region. You can choose Region Tenant, Default Region, or Global Region and specify Other Region to enter a custom region you have defined.
Optionally, select Enable Bucket Versioning or Object Lock. These settings are disabled by default unless you Enable Bucket Versioning Tenant-wide in Tenant Settings. For more information about S3 bucket versioning, see the AWS documentation. It's important to note that while DuploCloud supports enabling versioning, managing versions and the deletion of versioned objects may require manual steps through the AWS console or CLI, especially since DuploCloud's current Terraform operations perform only basic delete operations.
Click Create. An S3 bucket is created.
Enable Bucket Versioning must be selected to use Object Lock. For environments not subject to compliance requirements, consider disabling versioning on buckets to simplify the creation and destruction of development tenants. However, disabling versioning does not delete existing versions.
You can configure the Tenant to enable bucket versioning by default.
In the DuploCloud Portal, navigate to Administrator -> Tenants.
Click on the Tenant name in the list.
In the Settings tab, click Add. The Add Tenant Feature pane displays.
Click Add. The Create an S3 Bucket pane displays.
From the Select Tenant Feature list box, select Default: Enable bucket versioning for new S3 buckets.
Select Enable.
Click Add. Bucket versioning will be enabled by default on the Create an S3 Bucket pane when creating a new S3 bucket.
With this setting configured, all new S3 buckets in the Tenant will automatically enable bucket versioning.
It is advisable to manage SES-specific buckets not managed by DuploCloud independently. Duplo's default bucket policy enforces encryption, which complements SES's automatic encryption for incoming emails.
You should manage your bucket policies if DuploCloud overwrites the custom policy to update an S3 Bucket defined in DuploCloud for SES.
Manage your S3 Bucket by setting managed_policies ignore in the DuploCloud Terraform provider, select Ignore bucket policies in the DuploCloud Portal when creating or editing your S3 Bucket.
You can set specific AWS S3 bucket permissions and policies using the DuploCloud Portal. Permissions for virtual machines, Lambda functions, and containers are provisioned automatically through Instance profiles, so no access key is required in your application code. However, when coding your application, be aware of these guidelines:
Use the IAM role or Instance profile to connect to services.
Only use the AWS SDK constructor for the region.
Set S3 Bucket permissions in the DuploCloud Portal:
In the DuploCloud Portal, navigate to Cloud Services -> Storage.
Click the S3 tab.
From the Name column, select the bucket for which you want to set permissions. The S3 Bucket page for your bucket displays.
In the Settings tab, click Edit. The Edit a S3 Bucket pane displays.
From the KMS list box, select the key management system scope (AWS Default KMS Key, Tenant KMS Key, etc.).
Select permissions: Allow Public Access, Enable Access Logs, or Enable Versioning. To enable access logs, additional configuration may be required, especially when integrating with Kubernetes ingress annotations.
Select an available Bucket Policy: Require SSL/HTTPS or Allow Public Read. To select the Allow Public Read policy, you must select the Allow Public Access permission. To ignore all bucket policies for the bucket, choose Ignore Bucket Policies.
Click Save. In the Details tab, your changed permissions are displayed.
From the S3 Bucket page, you can set bucket permissions directly in the AWS Console by clicking the >_Console icon. You have permission to configure the bucket within the AWS Console session, but no access or security-level permissions are available.
DuploCloud provides the capability to specify a custom prefix for S3 buckets, enhancing naming conventions and organizational strategies. Before adding custom prefixes, ensure the ENABLEAWSRESOURCEMGMTUSINGTAGS property is set to True in DuploCloud by contacting the DuploCloud Support Team using your Slack channel. This setting allows for a more tailored bucket naming approach that can reflect your organization's naming conventions or project identifiers.
Avoid specifying system-reserved prefixes such as duploservices.
In the DuploCloud Portal, navigate to Administrator -> System Settings.
Click the System Config tab.
Click Add. The Add Config pane displays.
From the Config Type list box, select AppConfig.
From the Key list box, select Prefix all S3 Bucket Names.
In the Value field, enter the custom prefix.
Click Submit.
When attempting to delete S3 buckets, it's crucial to first empty the bucket. DuploCloud is planning to introduce a "force delete data" feature to simplify this process, including version deletions. Until then, manual deletion through the AWS console is a reliable method for smaller buckets. For managing versions, users may need to use the AWS CLI, as DuploCloud's Terraform operations currently only perform basic delete operations.
You can create S3 bucket replication rules for AWS from within the DuploCloud Portal. These rules allow you to automatically replicate objects across buckets, either within the same region or across different regions. Multiple replication rules are supported.
To create an S3 bucket replication rule in DuploCloud, follow these steps:
From the DuploCloud Portal, navigate to Cloud Services -> Storage.
Select the S3 tab.
In the NAME column, click the name of the bucket you want to create the replication rule for.
Select the Replication Rule tab, and click Add. The Add S3 Bucket Replication pane displays.
In the Add S3 Bucket Replication pane, complete the following fields:
Rule Name: Enter a descriptive name for the replication rule.
Tenants: Select the tenant to associate with the replication rule.
Destination S3 Bucket: Choose the destination bucket where the objects from the source bucket will be replicated. This can be in the same or a different AWS region.
Priority: Set the priority for this rule. The lower the number, the higher the priority.
Optionally, enable Delete Marker Replication: this option replicates delete markers from the source bucket to the destination bucket.
Optionally, enable Change Storage class for replicated objects: Enable this option if you want to change the storage class of the replicated objects. Then, select the desired Storage Class (e.g., Standard, Glacier, etc.).
Click Save to apply the replication rule.
From the DuploCloud Portal, navigate to Cloud Services -> Storage.
Select the S3 tab.
In the NAME column, click the name of the bucket you want to view replication rules for.
Select the Replication Rule tab. The replication rules applied to the selected S3 bucket are displayed.
Configure Apache Airflow for AWS
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) orchestrates your workflows using Directed Acyclic Graphs (DAGs) written in Python. You provide MWAA an Amazon S3 bucket where your DAGs, plugins, and Python requirements reside. You can run and monitor your DAGs using the AWS Management Console, a command line interface (CLI), a software development kit (SDK), or the Apache Airflow user interface (UI).
Create a S3 bucket by following the steps here.
Package and upload your DAG (Directed Acyclic Graph) code to Amazon S3. Amazon MWAA loads the following folders and files into Airflow.
Ensure Versioning is enabled for the custom plugins in a plugins.zip, the startup shell script file and Python dependencies in a requirements.txt on your Amazon S3 bucket.
Refer to the Amazon documentation on DAGs for more details.
In the DuploCloud Portal, navigate to Cloud Services -> Analytics.
Click the Airflow tab.
Click Add. The New Managed Airflow Environment wizard displays.
Provide the required information, such as Airflow Environment Name, Airflow Version, S3 bucket, and DAGs folder location by navigating through the wizard. You can also enable Logging for Managed Airflow.
If you specify plugins.zip, requirements.txt, and startup script while setting up the Airflow Environment, you must provide the S3 Version ID of these files (for example, lSHNqFtO5Z7_6K6YfGpKnpyjqP2JTvSf). If the Version ID is blank, the default reference is to the latest Version ID of the files specified from S3 Bucket.
After setup, view the Managed Airflow Environment from the DuploCloud Portal, using the Airflow tab. You can view the Airflow Environment in the AWS Console by clicking the WebserverURL.
Using Amazon SQS in DuploCloud
Amazon Simple Queue Service (Amazon SQS) offers a secure, durable, and available hosted queue to integrate and decouple distributed software systems and components. It provides a generic web service API that you can access using any programming language that AWS SDK supports.
The following Amazon SQS Queue types are supported.
Standard Queues - Standard queues support a nearly unlimited number of API calls per second, per API action (SendMessage, ReceiveMessage, or DeleteMessage). Standard queues support at-least-once message delivery. However, occasionally (because of the highly distributed architecture that allows nearly unlimited throughput), more than one copy of a message might be delivered out of order. Standard queues provide best-effort ordering which ensures that messages are generally delivered in the same order as they're sent.
FIFO Queues - FIFO queues have all the capabilities of a Standard queue, but are designed to enhance messaging between applications when the order of operations and events is critical, or where duplicates cannot be tolerated.
in the DuploCloud portal, navigate to Cloud Services -> App Integration.
Click the SQS tab.
Click Add. The Create a SQS Queue pane displays.
Enter an SQS Queue Name.
Select Standard from the Queue Type list box.
Enter Message Retention Period (in Seconds). For example, 345600 seconds in the example equates to four days.
Enter the Visibility Timeout in seconds. In the example, we specify 30 seconds.
Optionally, select Configure Dead Letter Queue, select the Target SQS dead letter queue, and specify the number of Message process attempts before dead letter queue.
Click Create.
In the DuploCloud portal, navigate to Cloud Services -> App Integration.
Click the SQS tab.
Click Add. The Create a SQS Queue pane displays.
Enter an SQS Queue Name.
Select FIFO from the Queue Type list box.
Enter Message Retention Period (in Seconds). For example, 345600 seconds in the example below equates to four days.
Enter the Visibility Timeout in seconds. In the example below, we specify 30 seconds.
Optionally, select Content-based deduplication. Selecting this option indicates that message deduplication IDs are used to ensure duplicate messages are not sent. If a message deduplication ID is sent successfully, any messages sent with the same message ID aren't delivered within five minutes.
Select either Queue or Message group from the Deduplication scope list box:
Queue: Deduplication processing occurs at the Queue level. The FIFO throughput limit is automatically set to Per queue.
Optionally, select Configure Dead Letter Queue, select the Target SQS dead letter queue, and specify the number of Message process attempts before dead letter queue.
Click Create.
You can configure a Dead Letter Queue (DLQ) and a redrive policy to manage messages that cannot be processed successfully. A DLQ stores failed messages, preventing them from blocking the normal operation of the queue. The redrive policy allows you to define how many times a message can be retried before it is moved to the DLQ. This feature enhances the reliability and manageability of your message processing system.
You can configure a Dead Letter Queue and redrive policy either when creating a new SQS or SQS FIFO queue or by editing an existing queue:
To edit an existing queue and configure the DLQ and redrive policy, use the procedure provided below.
Select the name of the Tenant that contains the SQS or SQS FIFO queue from the Tenant list box.
Navigate to Cloud Services -> App Integration.
Select the SQS tab.
Select the name of the SQS or SQS FIFO queue from the NAME column.
Click on the Actions menu, and select Edit. The Edit SQS Queue or Edit SQS FIFO Queue pane displays.
Enable Configure Dead Letter Queue.
Select the Target SQS dead letter queue.
Specify the number of Message process attempts before dead letter queue.
Click Update. The DQL and redrive settings for the SQS or SQS FIFO queue are configured.
Creating and Using a WAF in DuploCloud AWS
The creation of a Web Application Firewall (WAF) is a one-time process. Create a WAF in the public cloud Console, fetch the ID/ARN, and update the Plan in DuploCloud. Once updated, the WAF can be attached to the Load Balancer.
When you create a WAF in DuploCloud, an entry is added to the . You use this entry to attach an ALB Load Balancer to your WAF.
In the DuploCloud Portal, navigate to Administrator -> Plans. The Plans page displays.
From the Name column, select the Plan you want to update.
Click the WAF tab.
Click Add. The Add WAF pane displays.
In the Name field, type the name of your WAF.
In the WAF ARN field, enter the Amazon Resource Name (ARN).
Optionally, enter your WAF Dashboard URL.
Click Create.
Only ALB Load Balancers can be attached to a WAF.
In the Other Settings card, click Edit. The Other Load Balancer Settings pane displays.
Complete the other required fields in the Other Load Balancer Settings pane.
Click Update.
From the DuploCloud portal, navigate to Administrator -> Plans.
From the Name column, select the Plan associated with the WAF you want to update.
Click the WAF tab.
Update the Name and/or WAF ARN.
Update or add a WAF Dashboard URL.
Click Update. The WAF is updated.
DuploCloud also provides a WAF Dashboard through which you can analyze the traffic that is coming in and the requests that are blocked. The Dashboard can be accessed from the left navigation panel: Observability -> WAF.
Enable AWS NAT Gateway for High Availability (HA)
Use NAT gateways so that instances in a private subnet can connect to services outside your Virtual Private Cloud (VPC). External services cannot initiate a connection with these instances.
See this for more information on NAT Gateways.
In the DuploCloud Portal, navigate to Administrator -> Infrastructure. The Infrastructure page displays.
Select the Infrastructure for which you want to enable NAT Gateway from the Name column.
Click the Settings tab.
Click Add. The Infra - Set Custom Data pane displays.
In the Setting Name field, select Enable HA NAT Gateway from the list box.
Select Enable.
Click Set.
Creating SNS Topics
A SNS Topic is a logical access point that acts as a communication channel. It lets you group multiple endpoints (such as , , HTTP/S, or an email address).
In the DuploCloud Portal, navigate to Cloud Services -> App Integration.
Click Add. The Create a SNS Topic pane displays.
In the Name field, enter the SNS Topic name.
If you plan to select FIFO Mode, your SNS topic must end with the .fifo suffix, for example my-topic.fifo, to indicate that it is a FIFO (First-In, First-Out) Topic. Without this suffix, the topic will be treated as a standard topic.
From the Encryption Key list box, select a key.
Optionally, select FIFO Mode and Enable FIFO content based deduplication.
FIFO Mode: Ensures that messages are processed in the exact order they are sent.
Enable FIFO content-based deduplication: Prevents duplicate messages from being delivered to the subscribers if the same message content is sent within a 5-minute window.
Click Create.
SNS Topic Alerts provide a flexible and scalable means of sending notifications and alerts across different AWS services and external endpoints, allowing you to stay informed about important events and incidents happening in your AWS environment.
Connect two VPCs for communication using private IP addresses
VPC is a networking connection between two VPCs enabling traffic to be routed between them. When you use VPC peering, instances in the VPCs communicate with each other as if they are in the same network. The VPCs can be in different regions (also known as Inter-Region VPC peering connections).
VPC peering facilitates the transfer of data. For example, if you have more than one AWS account, you can peer the VPCs across those accounts and create a file-sharing network.
This procedure describes how to peer two VPCs, using subnet routes, and how to manage the peering connections and routes. For detailed steps on setting up VPC peering in Duplo, refer to the .
Enable VPCs for peering:
We will be referring following steps to peer 2 VPCs VPC-A and VPC-B.
In the DuploCloud Portal, navigate to Administrator -> Infrastructure. The Infrastructure page displays. In this example, the Infrastructures are named VPC-A and VPC-B.
From the Name column, select the first Infrastructure (VPC-A) for which to enable peering. VPC-A and its defined subnet routes are displayed.
Click the Peering tab and the VPC Peering page displays.\
From the Choose VPC list box, select a VPC that you want to peer with VPC-A. In this example, we select VPC-B.
Select the Is Peered checkbox.
Click Save. \
Click on Peer again.
Follow similar from the above-listed steps 2 to 6 for VPC-B Infrastructure.
Now that your two VPCs (VPC-A and VPC-B) are connected, define the subnet routes that the VPCs use for communication.
To begin, on the VPC Peering page for the first VPC that you set up (VPC-A), click Peer again. The Infrastructure page displays.
Click the Peering tab and the VPC Peering page displays.
Select the Choose VPC list box. The second VPC (VPC-B) displays in the list box and the Is Peered checkbox is selected, indicating that you previously connected the first VPC (VPC-A) with the second VPC (VPC-B) for peering.
Select the subnet routes that you want to define for VPC peering communication between the two VPCs (VPC-A and VPC-B). In this example, we select the checkboxes for subnet routes vpc-B-a-private and vpc-B-a-public. \
Click Save.
Click Peer again and repeat the numbered procedure above to peer the VPC-B Infrastructure.
Confirm that your two VPCs are enabled for peering, are connected with each other, and have subnet routes defined for communication.
In the DuploCloud Portal, navigate to Administrator -> Infrastructure. The Infrastructure page displays.
Click the Peering tab and the VPC Peering page displays.
Select the Choose VPC list box to confirm that VPC-B is peered with VPC-A and uses the subnet routes you defined. The name of the second VPC (VPC-B) displays in the list box and the Is Peered checkbox is selected. The subnet routes that you selected are displayed as checked.\
Click Save.
To maintain accessibility, add Security Group rules for Tenant VPC zones:
In the DuploCloud Portal, navigate to Administrator -> Infrastructure.
Select the Infrastructure from the Name column.
Click the Security Group Rules tab. \
Click Add. The Add Tenant Security pane opens.\
Define the rule for your Port Range and click Add.
Delete subnet routes that you defined for VPC peer-to-peer communication:
In the DuploCloud Portal, navigate to Administrator -> Infrastructure. The Infrastructure page displays.
Click the Peering tab. The VPC Peering page displays for VPC-A.\
Select the Choose VPC list box. The peered VPC (VPC-B) displays and the Is Peered checkbox is selected along with the associated subnet routes defined for communication.
Clear the checkboxes of the subnet routes you want to remove in the Select Subnets column. Using the CTRL key, you can select multiple checkboxes and clear them with a single click. In this example, we remove the subnet route vpc-b-A-private by clearing its checkbox.\
Click Save. The subnet route vpc-b-A-private has been removed for VPC-A/VPC-B peering.
Delete the peering connection between VPCs:
In the DuploCloud Portal, navigate to Administrator -> Infrastructure. The Infrastructure page displays.
Click the Peering tab. The VPC Peering page displays for VPC-A.\
Select the Choose VPC list box. The peered VPC (VPC-B) displays and the Is Peered checkbox is selected along with the associated subnet routes defined for communication.
Clear the Is Peered checkbox. \
Click Save. The Select Subnets list no longer displays and the peering connection between VPC-A and VPC-B has been removed.
Complete details of this feature are available in the Kubernetes documentation .
Enable Kubernetes Health by adding a .
On the EMR Serverless page, click the menu () icon and select Clone.
If you are new to Spark, use the Info Tips (blue icon) when entering data in the EMR Serverless configuration wizard steps below.
Message group: Deduplication processing occurs at the level, using Message group IDs. In the FIFO throughput limit list box, select Per queue or Per message group ID to specify whether the FIFO Throughput Quota applies to the entire FIFO Queue or individually to each Message Group.
To configure DLQ and redrive policy during queue creation, follow the instructions above to create an or . Select Configure Dead Letter Queue, select the Target SQS dead letter queue, and specify the number of Message process attempts before dead letter queue.
If you don't yet have an Application Load Balancer (ALB), .
From the Web ACL list box, select a .
Click on the menu icon () in the row of the existing WAF that you want to update, and select Edit. The Update WAF YOUR_WAF_NAME pane displays.
To set alerts for SNS Topics, .
SNS Topics are used in event processing in conjunction with DynamoDB and Lambda, among other services. See the for information, permissions information, and examples.
Select the Infrastructure (VPC-A) containing the first VPC that you for peering.
Select one of the Infrastructures containing a VPC that you previously for peering and for which you defined . In this example, we select VPC-A.
Select one of the Infrastructures containing a VPC that you previously for peering and for which you defined . Continuing the example above, in this case, we select VPC-A.
Optionally, confirm the deletion by .
Select one of the Infrastructures containing a VPC that you previously for peering and for which you defined . Continuing the example above, in this case, we select VPC-A.
Optionally, confirm the deletion by .